Напісаць гэты артыкул мяне натхніў дзённік з LiveJournal. Дзяўчына пыталася дзе можна знайсці беларускамоўны пакет да вядомай праграмы FineReader 8. І хоць з таго моманту мінула амаль чатыры гады і выйшла ўжо некалькі новых версіяў праграмы, але праблема з распазнаваннем тэкстаў на беларускай мове не вырашаная і да гэта часу.
Напэўна, цяжка знайсці чалавека, які актыўна карыстаецца камп'ютарам і не ведае пра праграму FineReader. Праграма з'яўляецца вельмі магутнай прыладай для пераводу папяровых дакументаў, фотаздымкаў і PDF (а таксама DjVu) файлаў у звычайны тэкст. Але гэта не ўсё, на што яна здольная. У апошніх версіях з'явілася магчымасць апрацоўваць дакументы дрэннай якасці і распазнаваць тэксты са складанай структурай. Напрыклад, якія змяшчаюць табліцы, малюнкі і ня надта складаныя формулы. Зразумела, што без удзелу чалавека пакуль не абыйсціся, але яно з'яўляецца мінімальным і больш-менш складаны тэкст можна адрэдагаваць за некалькі хвілін (пры ўмове, што вы бачыце праграму не ў першы раз). На сённяшні момант праграма падтрымлівае 189 моў, 36 з іх з'яўляюцца асноўнымі, г.зн. маюць слоўнікавую падтрымку. На жаль, беларуская мова не з'яўляецца асноўнай, і якасць распазнавання тэкстаў без падтрымкі слоўнікаў вельмі пасрэдная. Больш за тое, спецыялісты кампаніі не ведаюць, што ў беларускай мове існуюць тры плыні правапісу: правапіс лацінкай, сучасны правапіс (наркамаўка), класічны правапіс (тарашкевіца). І напрыклад, калі Вы маеце кнігу ў фармаце PDF/DjVu, напісаную беларускай лацінкай, напэўна, ў вас з'явяцца цяжкасці з пераводам яе ў звычайны тэкст. Я некалькі разоў звяртаўся да распрацоўшчыкаў праграмы з прапановай азначыць хаця б усе тры беларускамоўныя правапісы без слоўнікавай падтрымкі, але мне заўсёды адмаўлялі, спасылаўшыся на тое, што камерцыйнай зацікаўленасці з боку беларускамоўнага насельніцтва і дзяржавы да праграмы FineReader няма, і ўводзіць яе зараз не мэтазгодна. Наколькі я зразумеў, я не першы, хто звярнуўся з такой прапановай. У Google я знайшоў цікавы артыкул, які быў надрукаваны ў газеце "Звязда", у якім ідзе размова не толькі пра тое, чаму няма адпаведнай падтрымкі беларускай мовы ў праграме FineReader, але ўвогуле пра стан беларускай мовы ў камп'ютарным свеце.
І пасля таго, як я быў цвёрда перакананы, што нашая дзяржава не зацікаўленая ў падтрымцы нацыянальнай мовы, а спецыялісты з кампаніі ABBYY далі зразумець, што яны пачнуць нешта змяняць толькі калі будзе буйная камерцыйная замова на іх прадукт, я пачаў шукаць выйсця з сітуацыі самастойна, бо мяне, шчыра кажучы, не задавальняла тая якасць распазнавання тэкстаў, якую прапаноўвала праграма па змаўчанні. Падчас распазнавання праграма часта памылялася і патрабавала майго ўдзелу. Было зразумела адно, што без слоўнікавай падтрымкі не абыйсціся... І я вырашыў зрабіць яе самастойна. Больш за тое, я паставіў перад сабой мэту штучна ўвесці ўсе тры беларускія правапісы.
Перш за ўсё, трэба было знайсці файлы са слоўнікамі ўсіх трох беларускіх плыняў. Натуральна, што адзіная ўмова - гэта памер файла са слоўнікам. Чым ён большы, тым лепш. Крыху пашукаўшы, я знайшоў на сваім цвёрдым дыску адпаведныя слоўнікавыя файлы. Праграма FineReader у мяне была ўсталяваная (я карыстаюся FineReader 11), і таму заставалася толькі ўбудаваць слоўнікі ў саму праграму. Дарэчы, яшчэ ў 9 версіі ў мяне не атрымлівалася гэта зрабіць: праграма імпартавала толькі частку слоў са слоўніка. У 10 і 11 версіі гэтых абмежаванняў ужо не было.
Давайце цяпер створым першую плынь для распазнання беларускіх тэкстаў, якія напісаныя сучасным правапісам.
Адчыняем FineReader, потым выбіраем у меню More languages.
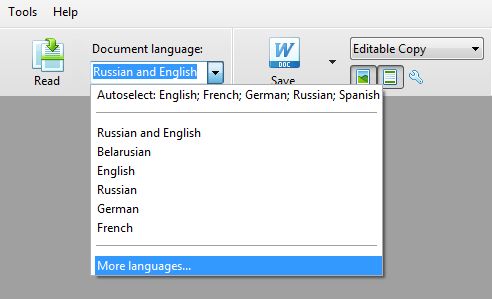
Перад намі з'явіцца вось такое акенца.
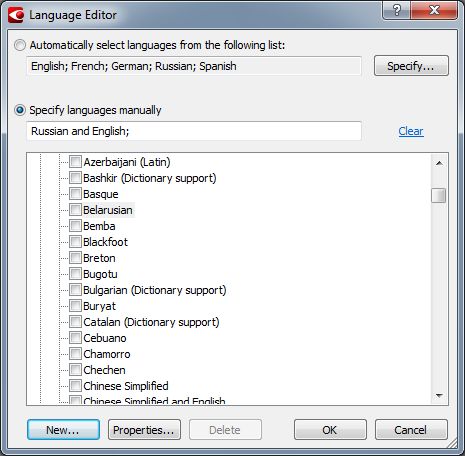
Выбіраем Belarusian і націскаем кнопку New... Націскаем OK.
У фінальным акенцы усе гатова для імпартавання нашага слоўніка.
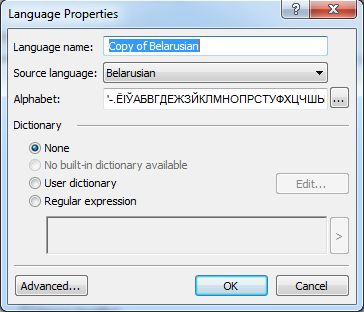
- Language name замест "Copy of Belarusian" я напісаў "Беларуская (сучасны правапіс)"
- Source language: Belarusian
- Alphabet - не змяняў
У рэшце рэшт, можна імпартаваць слоўнік Belarusian (Modern Spelling), усе слоўнікі можна спампаваць адсюль адным файлам. Выбіраем User dictionary > Edit... > Import і чакаем... У мяне не вельмі магутны камп'ютар, і таму імпартаванне слоўніка заняла дзесьці 5-6 хвілін. Кожны раз яго імпартаваць не прыйдзецца, а таму можна і пачакаць...
Пасля таго як імпарт будзе скончаны перад намі з'явіцца вось такое вакенца.
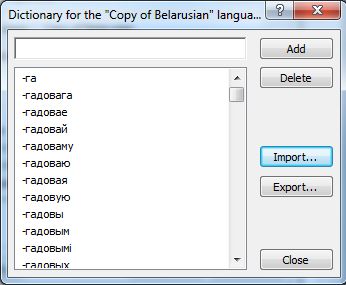
Усё! Цяпер можна распазнаваць тэксты на беларускай мове, напісаныя на сучасным правапісе. У мяне якасць распазнавання са слоўнікам падвысілася ў некалькі разоў.
Разгледзім цяпер стварэнне плыні з класічным правапісам беларускай мовы.
Я не буду перапісваць усё зноў, т.ш. працэс амаль што аднолькавы. Зраблю толькі некалькі заўваг.
Па-першае: у радку Language name замест "Copy of Belarusian" трэба напісаць "Беларуская (клясічны правапіс)", але я думаю, што гэта відавочна.
Па-другое: у радок Alphabet трэба дадаць літару Ґґ, якой няма ў сучасным правапісе.
Усё астатняе выконваецца па алгарытму дзе мы стваралі слоўнікавую падтрымку для сучаснага правапісу беларускай мовы. У выніку мы атрымалі магчымасць распазнаваць тэксты з дапамогай паўнавартаснага слоўніка ў класічным правапісе.
Давайце цяпер паглядзім, як можна імпартаваць беларускую лацінку ў FineReader.
Пра тое, што пісаць можна не толькі кірылічнымі літарамі па-беларуску, а і літарамі з лацінскага алфавіту напэўна ведае не кожны беларус (шчыра кажучы, не кожны беларус нават на элементарным узроўні валодае сучасным правапісам, не тое што лацінкай). А гэтая плынь была вельмі папулярная ў XIX стагоддзі. Дарэчы, менавіта на лацінцы была надрукаваная першая беларуская газета "Мужыцкая праўда". Выконваем ўсе крокі, якія мы выконвалі пры ўбудаванні слоўніка з сучасным правапісам.
- Language name замест "Copy of Belarusian" пішам "Беларуская (лацінка)"
- Source language: Belarusian
- Alphabet - вось тут трэба замяніць яго ўвесь. Я спецыяльна падрыхтаваў алфавіт для лацінкі. Вам патрабуецца толькі скапіяваць яго і ўставіць у радок Alphabet у праграме FineReader.
- Маем: ' -.ЁІЎАБВГДЕЖЗЙКЛМНОПРСТУФХЦЧШЫЬЭЮЯабвгдежзйклмнопрстуфхцчшыьэюяёіў'
- Замяняем: '-.ABC??DEFGHIJKL?MN?OPRS??TU?VYZ??abc??defghijkl?mn?oprs??tu?vyz??'
Пасля гэтага можна імпартаваць слоўнік Belarusian (latin). Цяпер у нас з'явілася магчымасць распазнаваць тэксты на беларускай лацінцы.
Здаецца, год таму на сваім камп'ютары я знайшоў кнігу, якая ўбачыла свет ажно ў 1917 г. і звалася яна Bieіaruski prawapis. Кніга складалася з 20 старонак, а важыла прыблізна 65 мегабайтаў. Дык вось, з дапамогай FineReader і слоўнікавай падтрымкі я распазнаў яе і перавёў у фармат DOCX. Вынік мяне ўразіў... Кніга стала важыць 55 кілабайтаў. Гэта яшчэ раз падкрэслівае, што FineReader вельмі магутная і гнуткая прылада, якая з лёгкасцю дазваляе распазнаваць любыя тэксты, у тым ліку і на беларускай мове.
Канечне, мяне вельмі засмучае (і, спадзяюся, не толькі мяне) той факт, што мы жывём у XXI стагоддзі, а карыстацца роднай мовай (пісаць тэксты з падтрымкай беларускага правапісу, карыстацца праграмамі сінтэзу маўлення беларускай мовы, распазнаваць тэксты на беларускай мове, карыстацца якаснымі перакладамі праграм на беларускую мову) на камп'ютары паўнавартасна не можам. І зразумела, што адзін, два, тры... нават дзесяць чалавек гэтую праблему не вырашаць. Звычайна, калі ідзе размова пра такія буйныя карпарацыі накшталт Microsoft, ABBYY, Oracle, Adobe і г.д., то ініцыятыва павінна ісці ад дзяржавы. На жаль, гэтага мы пакуль не бачым і напэўна яшчэ хутка ня ўбачым...
P.S. Калі вам спадабаўся мой артыкул і вы хочаце аддзякаваць мяне, проста адскануйце цікавую кнігу на беларускай мове, якасна распазнайце яе з дапамогай FineReader з папярэдне ўбудаванымі слоўнікамі і пакладзіце ў Інтэрнэт або дашліце мне на электронную пошту [email protected].
Да сустрэчы на старонках любімай газеты!
Аляксандр КОШАЛЬ





















Комментарии
Эммм... А если в текстовом формате, да еще и сжать... Только зачем при нынешних объемах накопителей? Что такое 65 МБ? Десяток фотографий.