Использование цифровой камеры для фотографирования текста
В научной и учебной работе нам приходится иметь дело с довольно большими объемами информации. Наиболее удобная и дешевая форма хранения информации - это электронная. К большому сожалению, не всю требуемую информацию мы можем получать в электронном виде. Большинство бумажных книг и журналов, особенно старых, до сих пор не имеет электронных версий. Поэтому нам самим приходится выполнять работу по цифровому копированию текста. Сначала мы использовали сканер Mustek ScanExpress 1200 USB Plus, затем, устав от длительного копирования, решили попробовать применить для этих целей недорогую цифровую камеру.
Идея использовать цифровые камеры для оцифровки текста известна давно. Широкому распространению этого метода копирования препятствовала высокая цена камер. В последнее время на рынке появилось много моделей недорогих цифровых камер. Ценовые тенденции, а также наши успешные эксперименты с цифровой камерой позволяют предположить, что в ближайшее время произойдет бум, связанный с массовым цифровым фотографированием текста.
Предпосылки использования
цифровой камеры для
фотографирования текста
Сканирование страницы текста формата А4 (210х297 мм) на недорогом сканере обычно занимает 30-40 с, поэтому для сканирования большого числа страниц требуется достаточно много времени. Например, сканирование книги в 600 страниц занимает более 6 часов.
Время, затрачиваемое цифровой камерой на съемку одного кадра, составляет несколько секунд. Для камеры Mustek MDC-3500 это 4 с. На съемку тех же 600 страниц уходит около 40 мин.
По нашему опыту, сканирование большинства книг лучше всего проводить с разрешением не менее 150 точек на дюйм (dpi). Изображение страницы формата А4, снятое при разрешении 150 dpi, содержит примерно 2 миллиона точек (пикселов). Значит, для фотографирования подходит камера с матрицей не менее 2 мегапикселов. По этой причине мы приобрели камеру Mustek MDC-3500 с матрицей 2,1 мегапикселов. На момент покупки камера была наиболее дешевой в своем классе.
Подготовительные работы
Прежде, чем использовать камеру, необходимо раздобыть штатив, изготовить оправы, вставить в них насадочные линзы и подготовить осветительную аппаратуру.
 Для удобства работы
камеру желательно закрепить. Для
этого из стержней, оставшихся от
старого принтера, мы изготовили
разборный штатив (см. рис.). Высота
штатива выбирается такой, чтобы в
поле зрения камеры целиком попадал
лист формата А4. Для нашей камеры
это 40 см.
Для удобства работы
камеру желательно закрепить. Для
этого из стержней, оставшихся от
старого принтера, мы изготовили
разборный штатив (см. рис.). Высота
штатива выбирается такой, чтобы в
поле зрения камеры целиком попадал
лист формата А4. Для нашей камеры
это 40 см.
Следующий шаг - доработка оптики.
Камера Mustek MDC-3500, как и большинство "мыльниц", имеет 2 фиксированных расстояния съемки. По нашим измерениям, наилучшее расстояние для съемки близких объектов - это b = 0,20 м. Если снимать страницу А4 целиком (с расстояния а = 0,40 м), то изображение получается размытым. Поэтому перед объективом камеры надо установить дополнительную линзу. По формулам из школьной оптики получается, что оптическая сила линзы должна быть D=(b-a)/(ab)= -2,5 диоптрий. Для крепления линзы мы изготовили дюралюминиевую оправу (см. рис.).
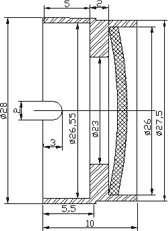
В ближайшем салоне "Оптика" за 1,5 евро в оправу вставили требуемую очковую линзу, которую приклеили клеящим пистолетом к предварительно разогретой оправе.
Мы изготовили сразу две насадочных линзы, вторая имеет оптическую силу -1,5 диоптрий. О ней - чуть позже.
Теперь об освещении. Мы используем две настольных лампы по 100 Вт, чтобы в середине разворота книги не было теней.
Съемка
Для ускорения последующей обработки изображений важно, чтобы все кадры были сняты единообразно. Поэтому при съемке отключаем вспышку и автоматическую цветовую коррекцию. Выдержку подбираем вручную. Разрешение устанавливаем 2 мегапиксела. При фотографировании надо тщательно следить за тем, чтобы книга находилась в одном и том же положении.
Во время съемки используем аккумуляторы с емкостью 750 мАч, двух комплектов которых хватает на съемку примерно 1000 страниц при выключенном дисплее. Дисплей нужен только для периодического контроля.
Обработка изображений
Кадры, отснятые камерой, - это цветные фотографии в формате JPEG. Их необходимо обрезать по краям и выровнять. Обычно требуется улучшить читаемость текста. Чтобы уменьшить размер файла, изображение необходимо преобразовать в черно-белое. И, наконец, для удобства последующей работы одиночные фотографии можно собрать в электронную книгу.
Мы не делаем распознавание текста из-за возможных ошибок. На их поиск и устранение уходит много времени, особенно если текст содержит формулы.
Обработку проводим в русифицированном Photoshop 5.0 или 6.0 на компьютере с процессором Athlon 1333. Сначала обрабатываем одну пробную страницу и при этом записываем свои действия. Затем эти действия повторяем со всеми страницами, но уже в автоматическом режиме.
Итак,
- Открываем изображение одного из кадров.
- Включаем запись наших действий: а) Окно -> Показать действия; б) в открывшемся окне: Создать новое действие.
- На фотографии выделяем прямоугольную область текста с небольшим запасом (инструмент - прямоугольная область).
- Обрезаем ненужное: Изображение -> Обрезать.
- Делаем черно-белое фото: Изображение->Режим->Оттенки Серого.
- Изменяем разрешение: Изображение->Размер изображения...->200 dpi.
- Выравниваем фон: Фильтр->Другой->Высокий проход... ->радиус примерно 30.
- Подбираем порог: Изображение->Корректировать->Порог...->выбираем приемлемое значение параметра.
- Останавливаем запись действий.
- Закрываем без сохранения рабочий файл.
- Обрабатываем все фото: Файл->Автоматизировать->Пакет...->устанавливаем Источник - Папка, выбираем адрес; устанавливаем Приемник - Папка, указываем адрес. В пункте "Воспроизвести" указываем имя записанного действия, в пункте "Имя" файла пишем: Имя документа + .jpg. OK.
Теперь все страницы желательно немного выровнять. С этой функцией хорошо справляется Fine Reader 6.0. Поэтому файлы открываем именно в нем, а затем выделяем все страницы и сохраняем изображение в один файл как TIFF черно-белый Group 4.
На рисунке представлен пример обработки фрагмента текста, снятого при разрешении 200 dpi.
 |
 |
 |
| До обработки | Обработка в Photoshop |
Обработка FineReader |
Заключительный этап для тех, кто не знаком с форматом DJVU. Открываем полученный файл в редакторе Adobe Acrobat 5.0 и сохраняем наш файл как PDF. Электронная книга готова.
Заключительные замечания
Если разрешение изображения 200 dpi и больше, Fine Reader хорошо распознает текст. Однако с таким разрешением можно снять страницу размерами не более 22х15 см. Съемка производится с насадочной линзой -1,5 диоптрий с расстояния 0,30 м.
Съемку в библиотеке хорошо проводить у окна при рассеянном освещении. Вся автоматика, кроме вспышки, должна быть включена. Камера Mustek MDC-3500 позволяет проводить съемку и при плохом освещении. При этом увеличивается выдержка, и для получения несмазанного изображения очень желательно иметь жесткий штатив.
Камера Mustek MDC-3500 имеет встроенную память 16 Мб, позволяющую хранить 50 снимков. Для ускорения съемки, чтобы лишний раз не прерывать процесс из-за перекачки информации в компьютер, а также для работы в библиотеке лучше докупить память. При использовании дополнительной памяти 256 Мб в камере можно хранить около 800 снимков.
Камеры с матрицами 3 мегапиксела и более позволяют получать фотографии с гораздо более высоким качеством. Чего вам и желаем.
Михаил СИЛЕНКОВ,
Геннадий ФАТЕЕВ,
[email protected]











Комментарии
использовать иструмент Crop. Также можно подправить Levels (уровни)
вручную Ctrl+L или автоматически Shift+Ctrl+L.
ничем не заменишь ........а приведенный пример просто порно какоето
>возможных ошибок. На их поиск и
>устранение уходит много времени, особенно
>если текст содержит формулы.
И зачем это тогда нужно?
Формат любопытный - текст очищает, а вот фото можно паковать с лучшим качеством. Можно накладывать в файл слоем и распознанный текст тоже, но это нужно платить или делать довольно запутанно.
и текст этот отдельным слоем н особенно полезен.... :)))
ну если только припрет из электронной книги куски в ворд кидать да и то можно распознать нужное место :)
А хорошая камера стоит дорого.
К тому же может кто-нибудь сказать каков ресурс у цифровика ... У них затворчик-то тоже механический и как я понимаю матрица тоже может вырождаться..