(Продолжение. Начало в №7-9, 11, 12)
Сегодня речь пойдет о лингвистическом пакете "ЮрИнформ".
В предыдущих версиях "ЮрИнформ" существовала возможность поиска документа по заданному пользователем одному или нескольким словам. Этот вид поиска был основан на последовательном переборе слов в текстах документов и их анализе на соответствие заданным критериям. Понятно, что поиск слова в такой объемной базе данных занимает длительное время, поэтому, для ускорения данной операции, пользователь, как правило, старался перед ее проведением максимально сузить область, в которой она проводилась (предварительно отобрав документы по виду и т. п.). Сегодня в версию "ЮрИнформ-professional" включен лингвистический пакет, который позволяет проводить поиск по слову практически молниеносно. Причем пользователь при задании параметров поиска сможет указать, учитывать ли при его выполнении отдельные морфологические части (окончания, суффиксы, приставки).
За счет чего это достигнуто? Дело в том, что над БД "Документы" проведена операция морфологического анализа содержащихся в ней слов, а также проведена индексация слов во всех текстах. Комплекс БД пополнился базами корней, приставок, суффиксов и окончаний.
Поиск в лингвистическом пакете не был бы таким быстрым, если бы не проведенная индексация слов. Структура связей комплекса БД, участвующих в лингвистическом поиске, приведена на схеме и выглядит следующим образом. Все корни слов, составляющих документы, в системе сведены в особую БД. Записи БД "Слова" содержат поля реляционных ссылок на БД "Корни". Между БД "Слова" и БД "Документы" помещена база-переходник (результат проведенной над ИПС индексации), указывающая, какие слова к каким документам относятся (см.рис.).
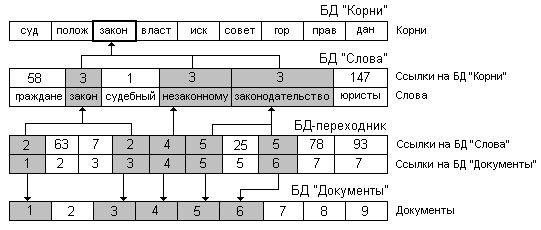
Рассмотрим действия СУБД при проведении пользователем лингвистического поиска. Допустим, пользователь желает получить список документов, тексты которых содержат слова с корнем "закон". С помощью операции проекции, которая проводится из базы "Корни" на базу "Слова", выделяются записи, содержащие данный корень (слова "закон", "законы", "подзаконный", "незаконному" и т. д.). На этом этапе, если в качестве параметров поиска указаны прочие морфологические части слова, во множестве однокоренных слов происходят соответствующие уточнения. Дальнейшей проекцией через базу переходник на БД "Документы" формируется желаемый список документов. Здесь, как и во многих других случаях, быстроту выборки обеспечивает операция проекции LeoBase.
Для обеспечения корректности морфологического поиска поставщику ИПС необходимо учитывать, что содержание базы документов постоянно меняется, и если вовремя не добавлять новые связи и изменять старые, то, в отличие от поиска простым перебором слов, индексный поиск перестает быть корректным. Для того, чтобы этого не произошло, БД "Документы" периодически проверяется и база корней пополняется новыми элементами. Естественно, операция эта происходит в автоматическом режиме. Для пополнения переходника использована возможность определить триггер (процедуру) для отслеживания изменений в базе документов. Имея информацию о том, какие документы изменились в процессе обновления, мы можем проверить БД-переходник и внести исправления в нее нужным образом. Естественно, что переходник корректируется только в той части, где проходили изменения.
К абонентам "ЮрИнформ-Professional" все изменения попадают вместе с очередным обновлением, поддерживая на должном уровне качество морфологического разбора и поиска.
В настоящее время база-переходник между БД "Корни" и БД "Документы" занимает, как и следовало ожидать, довольно большой объем. Однако использование новых подходов, которые планируется воплотить в LeoBase, позволит существенно сократить ее объем. База-переходник, реализованная другим методом (за счет своеобразного сжатия), займет примерно в 4 раза меньше места по сравнению с сегодняшним ее размером.
В предыдущих публикациях мы на примере ИПС "ЮрИнформ" рассмотрели некоторые приемы, применяемые при создании прикладного проекта на LeoBase. Начиная со следующей статьи, мы будем рассказывать об устройстве самой СУБД и в следующий раз поговорим о структуре комплекса БД и о модели представления данных.
Владимир КОТЛЯРОВ,
"СофтИнформ", тел. 228-00-48,
e-mail: [email protected]










