Все уже знают, что в скором будущем (а именно в 1999 году) в семействе Intel ожидается пополнение. Известно, что новый процессор разрабатывается Intel совместно с Hewlett-Packard и называется Merced (по названию реки в Калифорнии). Циркулируют различные слухи по поводу архитектуры IA-64 (Intel architecture 64) и ее возможностей. В этой статье я постараюсь пролить свет на то, в чем мне удалось разобраться самому.
Начнем с того, что IA-64 не будет простым расширением 32-х битной архитектуры x86 (Intel) на просторы 64 бит. В то же время она не станет и одной из производных 64 битной архитектуры PA-RISC (Hewlett-Packard). По заявлениям компаний-разработчиков, IA-64 будет представлять собой нечто совершенно новое - помесь элементов RISC, VLIW, а также разных других излишеств. Intel даже придумал для нее новое название EPIC (Explicitly Parallel Instruction Computing, что в вольном переводе представляет собой вычисление с явным параллелизмом). При всем при том разработчики обещают сохранить для Merced возможность выполнять программы, написанные как для x86, так и для PA-RISC. Если эти обещания подтвердятся, то позиции Merced станут весьма прочны. Ведь именно из-за проблем совместимости в семействе x86 до сих пор передается по наследству множество недостатков, присущих первым моделям процессоров. Однако сам x86 пока тоже не собирается на пенсию - в один год с Merced ожидается выход его очередного представителя - Katmai.
Итак, что же нового ожидается в IA-64 и его первом представителе: процессоре Merced. С точки зрения техники: во-первых, в нем будет применяться 0.18 микронная технология, которую Intel к тому времени собирается довести до конвейера. Во-вторых количество транзисторов перевалит за десять миллионов. Однако большинство новых идей будет заключено именно в архитектуре. Как это ни удивительно, огромное число транзисторов на современных процессорах занято не самими вычислениями, а сопутствующими операциями: определением наиболее вероятного исхода операции ветвления (предсказанием ветвления) и т.д. Делается это для того, чтобы исполнять по возможности несколько команд параллельно (то есть одновременно). Но результат тут не очень утешителен: объем сопутствующей логики растет значительно быстрее степени параллелизма. Вторая проблема: медленный доступ к данным (то бишь к памяти). Тактовая частота при обмене с памятью (66 МГц сейчас, 100 - в ближайшем будущем) намного меньше внутренней частоты процессора (уже сегодня максимум - 333 МГц). Как же будут бороться с этими трудностями создатели Merced?
Во-первых, команды будут иметь фиксированную длину (как это принято в RISC-архитектуре) 128 бит (явное влияние VLIW - very long instruction word). Поскольку Intel считает, что расшифровка VLIW (очень длинные инструкции) имеет несколько отрицательный оттенок, а термин "RISC-подобные команды" тоже не звучит - была придумана аббревиатура EPIC, подразумевающая понемногу и того, и другого. На самом деле каждая 128 битная команда имеет достаточно сложную структуру, поскольку состоит из трех "настоящих" команд и нескольких дополнительных полей (см. рис. 1).
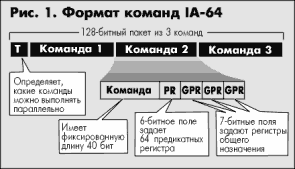
Эти поля будут служить для реализации изюминок IA-64: предикативного исполнения (predication) и заблаговременного считывания данных (speculative loading). Подробнее мы о них поговорим попозже, а сейчас надо обратить внимание на один весьма важный момент: откуда будут браться данные для заполнения таких полей? Их будет поставлять компилятор. Он же будет формировать пакеты команд таким образом, чтобы обеспечить максимально эффективное параллельное выполнение программ. Это значит, что на компилятор полностью будет переложена оптимизация создаваемого кода (отсюда и экономия на транзисторах сопутствующей логики). То, что раньше было задачей процессора, теперь станет реализовываться программным путем. Поэтому каждый конкретный процессор семейства IA-64 будет весьма тесно связан с соответствующим компилятором. Причем, требуемая степень оптимизации (и степень учета особенностей процессора) не может сравниться даже с компиляторами, использующимися в современных RISC-системах.
Посмотрим теперь, что же такое предикативное исполнение. Правда, начать придется издалека. Все знают, что программа - это последовательность команд, которые исполняются последовательно (потому и последовательность). Существуют специальные команды, позволяющие изменять порядок выполнения других команд - это команды условных и безусловных переходов. В первом случае переход (то есть пропуск определенного блока команд) осуществляется при выполнении некоторого условия (все это носит название ветвления). Для параллельного процессора выполнение таких команд представляет собой сложную задачу, поскольку из двух возможных исходов необходимо выбрать наиболее вероятный (для этого служат схемы предсказания ветвления) и исполнить соответствующую часть кода (учтите, что в момент выполнения этой части в одном канале, в другом будет выполняться код, содержащий условный оператор, который в конечном итоге определит правильность выбора). Причем, если выбор будет неверен, то придется загружать и исполнять код, соответствующий второй ветке. Все это выльется в потери времени, сравнимые с экономией, получаемой от предсказания ветвления. Собственно говоря, современный параллельный процессор, который должен выполнять параллельно за один такт четыре команды, на самом деле выполняет в среднем около двух.
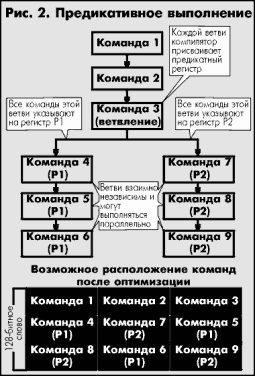
В Merced эта проблема решается следующим образом: параллельно выполняются обе возможные ветви. Собственно говоря, они могут выполняться и не совсем параллельно, поскольку команды, сформированные компилятором, будут следовать совсем не в том порядке, в каком они идут в программе (задача оптимизации в том и заключается, чтобы реализовать максимальный параллелизм). Безусловно, время, затраченное на исполнение неверной ветви, пропадет впустую, но зато к моменту выполнения условного оператора будут известны результаты вычислений в обеих ветвях. Понятно, что для хранения результатов выполнения нескольких ветвей надо много регистров. У Merced их будет 128 общего назначения и 128 для чисел с плавающей точкой. Процесс предикативного исполнения неплохо проиллюстрирован на рисунке 2.
Вторая отличительная черта IA-64 - предварительная загрузка данных. Компилятор будет формировать 128 битные пакеты таким образом, чтобы по возможности загружать данные из памяти до того, как они потребуются программе. Это позволит несколько сгладить разницу между медленной памятью и быстрым процессором - то есть облегчить задачу кэш-памяти. Правда, с предварительной загрузкой могут возникнуть проблемы - допустим, считанные данные в дальнейшем так и не потребуются. Для ее решения предусмотрен специальный механизм, позволяющий подтверждать правильность операции считывания. Правда, возникает вопрос, как отразится возможность заблаговременного считывания на работе общего кэша многопроцессорных систем. Но это пока что дело будущего. В целом же надо сказать, что многие идеи IA-64 не так уж новы, часть из них используется сейчас в процессорах семейства Power PC.
Константин
АФАНАСЬЕВ,
по материалам "BYTE"










