Принципы полнотекстового поиска
Говорить о поиске можно долго и со вкусом, потому что вряд ли есть сегодня тема более актуальная, чем поиск необходимого в современных огромных объемах информации. Впрочем, на этот вопрос тоже можно смотреть с разных сторон...
И совсем по-разному видят процессы поиска информации программист и пользователь: если для одного это просто ввести фразу и нажать кнопку, то для другого - это набор алгоритмов, достаточно сложных в большинстве случаев. Конечно, сегодня основные из них вряд ли могут считаться чем-то похожим на откровение даже с очень большой натяжкой - большинство из них сегодня изучаются студентами уже на младших курсах. С другой стороны, программистам вряд ли необходимо знание всех тех томов, которые посвящены разным видам поиска и которые можно найти в свободном доступе в Сети. Думаю, что людей с подобными, весьма специфическими, знаниями сегодня очень мало даже в тех компаниях, которые живут, по сути, за счет поиска - например, Google и Yahoo! Что, впрочем, не означает, что некоторые базовые знания в вопросах алгоритмов поиска не пригодятся программисту вовсе. Впрочем, сейчас мы будем говорить не столько об алгоритмах, сколько об основных принципах, знание которых расширит кругозор не только тех, кто причисляет себя к программистам.
Поиск поиску рознь
Конечно, говорить о поиске вообще - все равно, что говорить вообще о программировании. То есть, разговор получится достаточно беспредметным и вряд ли кому-то интересным именно в силу этого своего "качества". Видов же поиска так много, что говорить обо всех них в одной статье - это, опять-таки, просто лить воду. Так что мы с вами остановимся на одном конкретном виде поиска.
Реальность диктует свои условия программистам, и законы спроса-предложения применительно к видам поиска, наиболее востребованным сегодня, никто не отменял. Так получилось, что в наше время львиная доля информации, которую можно искать, представлена в текстовом виде, и поэтому большей частью именно в текстовой информации необходимо организовать какого-либо рода поиск. Вернее, даже, чаще всего, не просто какого-либо рода поиск, а вполне конкретный вид этого самого поиска - речь, конечно же, о полнотекстовом поиске.
Полнотекстовый поиск
Если обратиться к всенародно любимому источнику знаний, сиречь Википедии, которую многие справедливо не любят (что, впрочем, совсем не мешает им её втихомолку использовать), то можно узнать, что "полнотекстовый поиск - поиск документа в базе данных текстов на основании содержимого этих документов, а также совокупность методов оптимизации этого процесса". Что ж, сколько бы бочек ни катили на Википедию, в данном случае она нас отнюдь не подвела.
Действительно, суть полнотекстового поиска состоит в том, что в большом объеме текстовой информации нужно найти достаточно большой фрагмент, заданный в качестве образца, и сказать, в каком именно документе этот фрагмент был найден.
Казалось бы, в чем сложности? Нужно просмотреть последовательно все документы, проверить наличие строки, заданной в качестве поискового запроса, в каждом из них, ну а затем уже выдать на-гора список всех документов, в которых искомая фраза содержится. Вроде бы, действительно более чем просто.
На самом же деле, конечно, не так просто и безоблачно. Время, необходимое для сканирования каждого документа, достаточно велико, а потому такой поиск требовал бы просто чудовищного количества времени. И, что самое главное, если мы изменим хотя бы одну букву в нашем поисковом запросе, все придется начинать заново и опять тратить просто невообразимое количество времени на получение результатов. Было бы просто замечательно как-то этого избежать - сканировать содержимое всех документов всего лишь однократно, а затем специальным образом сохранять в упорядоченном виде всю информацию, полученную в результате такого сканирования, чтобы в будущем уже вести поиск именно с её помощью и не тратить лишнее время на повторное сканирование всех документов.
Именно эта нехитрая идея нашла свое отражение в использовании поисковых индексов, без которых невозможно представить себе работу ни одного современного "поисковика", начиная с обычного полнотекстового поиска по файлам, расположенным на компьютере, и заканчивая поисковыми машинами, работающими во Всемирной паутине. Довольно давно тому назад я уже рассказывал в общих чертах читателям "Компьютерных вестей" в рубрике FAQ о том, что представляют собой поисковые индексы. Тем не менее, думаю, будет совсем не лишним поговорить о них немного подробнее здесь и сейчас.
Поисковые индексы
Подавляющее большинство решений полнотекстового поиска требуют сегодня предварительной индексации текста. Конечно, у каждой современной системы полнотекстового поиска свое внутреннее устройство поискового индекса, показавшееся оптимальным её разработчикам. С другой стороны, все они работают по одним и тем же принципам, так что между ними, как ни крути, все-таки достаточно много общего.
Поисковый индекс можно рассматривать как своеобразный словарь, в котором каждому найденному в процессе индексации слову сопоставляется список документов, в котором оно найдено. Обычно учитываются также позиции найденного слова в этих самых документах - это чрезвычайно важно для поиска не по одному слову, а по целым фразам, особенно в тех случаях, когда учитывается порядок слов в фразе и расстояние между ними в тексте. То есть, поисковый индекс - это база данных, в которой все записывается примерно таким образом, как показано на иллюстрации к статье. Как видите, слово играет роль ключа - а если эти слова упорядочены по алфавиту, то время поиска существенно сокращается, по сравнению с тем, что было раньше - теперь, фактически, много времени занимает только построение индекса, а поиск по нему уже начинает быть существенно более быстрым.
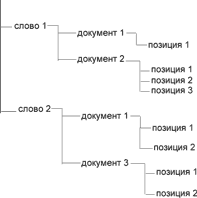
Реальные поисковые индексы, конечно же, устроены несколько сложнее, чем эта наша упрощенная модель. Обычно названия документов и сами слова выносятся в отдельные таблицы в базе данных, а в основной хранятся только соответствующие номера записей. Очень большие индексы зачастую сами подвергаются индексации - например, индексы web-"поисковиков", содержащие сотни тысяч и даже миллионы слов на самых разных языках, и десятки миллионов документов.
Индекс, составленный по описанному выше принципу, называется инверсным - потому что с его использованием поисковая система "идет" не от документов к словам, как в безындексном поиске, а наоборот - от слов к документам. Как правило, впрочем, этот индекс сопровождается для удобства пользователя еще вторым индексом - прямым. Дело в том, что сегодня в результатах поиска принято еще показывать цитату из оригинального документа, содержащую искомый текст. Вот именно для этого и нужен второй индекс - в нем и хранится (как правило, в сжатом виде) копия всех проиндексированных документов. Хотя иногда, если количество проиндексированных документов в базе не слишком велико, разумнее использовать не отдельный индекс, а восстанавливать кусок того текста, который "обрамляет" искомую строку, из инверсного индекса.
Впрочем, сегодня уже одним только поисковым индексом, ускоряющим поиск, никого не удивишь. Потому что пользователи, разбалованные удобством интернет-поисковиков, желают, чтобы в результатах были не только точно совпадающие с запросом фразы, но и ряд других, которые отличаются формами слов, а иногда даже содержат их синонимы. Так что сегодня качественные поисковые системы поддерживают две вещи - поиск с учетом морфологии и семантический поиск.
Дополнительные "навороты"
Поиск с учетом морфологии реализуется с помощью специального словаря, который содержит различные формы слов, хотя в ряде случаев и она не нужна. При индексации и при анализе поискового запроса "поисковик" преобразует слова в их первоначальную форму. При этом для восстановления словоформы в результатах поиска может использоваться как раз та самая таблица, с помощью которой "восстанавливается" первоначально использовавшаяся в тексте форма слова.
В целом, аналогичным образом реализован и поиск с использованием синонимов, который обычно компании-разработчики поисковых систем преподносят как "семантический поиск". Хотя, конечно, полноценный семантический поиск подразумевает под собой куда более глубокий анализ текста, который выходит за пределы этой статьи по причине того, что механизмы его достаточно сложны, и рассказ о них будет весьма объемным. Тем более, в силу сложности далеко не все поисковые системы могут сейчас предложить его своим пользователям. Тем не менее, даже поиск с дополнительными словарями, то есть с учетом морфологии и с поддержкой синонимов, уже значительно упрощает жизнь того, кто в итоге будет пользоваться такой поисковой системой.
На практике большая часть разработчиков так никогда и не сталкивается с необходимостью реализации собственных алгоритмов полнотекстового поиска, поскольку в силу трудоемкости такой задачи гораздо удобнее воспользоваться сторонними разработками, например, такими, как SearchInform SDK. Впрочем, рассказ об этом SDK, как и о семантическом поиске - это уже дело будущих номеров "Компьютерных вестей".
Вадим СТАНКЕВИЧ,
[email protected]










Комментарии