Термин NoSQL (англ. Not Only SQL - не только SQL) стал известен относительно недавно и был введен для описания различных технологий баз данных, возникших для удовлетворения требований, известных как "Web-scale" или "Internet-scale".
Есть три требования к Web-scale приложениям:
- Много данных: самые большие из веб-приложений обрабатывают объемы данных на порядки больше тех, что предполагались для управления базами данных (Facebook - 50 терабайт для поиска по входящим сообщениям; eBay - всего 2 петабайта)
- Огромное количество пользователей: исчисляются миллионами, доступ к системам одновременно и постоянно
- Сложные данные: как правило, это приложения не простой обработки табличных данных, которые можно найти во многих коммерческих и бизнес-приложениях.
Технологии реляционных баз данных, которые доминировали в ИТ-индустрии с 1980 года, начали показывать свои слабые места при переходе к веб-масштабам именно в этих трех аспектах, поэтому все большее число людей начали искать альтернативу. Так стали появляться NoSQL базы данных. Хотя разнообразие моделей растет, все они имеют общие черты:
- Обрабатывают огромные объемы данных, разделяя их между серверами
- Поддерживают огромное количество пользователей
- Используют упрощенную, более гибкую, не ограниченную схемой структуру базы данных
Все наиболее успешные и известные NoSQL базы данных были разработаны с нуля за последние несколько лет. Странно, но, похоже, что никто из разработчиков не посмотрел вокруг, чтобы увидеть, есть ли уже существующие, успешно реализованные технологии баз данных, которые могли бы обеспечить надежную основу для соответствия требованиям Web-scale.
Если бы они это сделали, то, возможно, обнаружили бы два продукта - GT.M (fisglobal.com/Products/TechnologyPlatforms/GTM/index.htm) и Inter-systems Cache (www.intersystems.ru), чьи системы хранения основаны на глобалах.
Краткий обзор глобалов
Глобал - это абстракция B-tree структуры, которая обычно используется в языке MUMPS (ru.wikipedia.org/wiki/MUMPS) для хранения больших объемов данных.
Глобалы изначально были разработаны в 1966 году для поддержки управления большими объемами сложных и слабоструктурированных медицинских данных, и были специально спроектированы для эффективной поддержки того, что тогда считалось невыполнимым - большого числа конкурентных интерактивных пользователей на серьезно ограниченных ресурсах PDP мини-компьютеров. Хотя это не "веб-масштаб", тем не менее, глобалы стали достижением, которое другие технологии баз данных в то время достичь не могли.
Характеристики глобалов:
- не ограничены схемой;
- иерархически структурированы;
- разреженные;
- динамические.
Для того чтобы понять, что такое глобал, представьте себе хранимый ассоциативный массив. Например:
account("New York", "026002561", 35120218433001)=123456.45
Общая форма выражения записывается следующим образом:
globalName(subscript1,subscript2,..subscriptN)=value
Такая комбинация имени, индексов и значения называется узлом глобала и является единицей хранения. Важным моментом является то, что один глобал может содержать узлы с разным количеством индексов, например:
myGlobal("a")=123
myGlobal("b","c1")="foo"
myGlobal("b","c2")="foo2"
myGlobal("d","e1","f1")="bar1"
myGlobal("d","e1","f2")="bar2"
myGlobal("d","e2","f1")="bar1"
myGlobal("d","e2","f2")="bar2"
myGlobal("d","e2","f3")="bar2"
То есть глобал представляет разреженное иерархическое дерево узлов. Например, глобал выше эффективно представляет следующее иерархическое дерево:
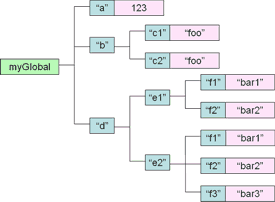
Вы можете создать любое количество глобалов. Другими словами, база данных в GT.M или Cache будет состоять из одного или множества глобалов, каждый со своей иерархией узлов.
В такой базе данных нет явных связей между глобалами, но могут быть неявные отношения, которые определяются и управляются на уровне приложения. Также не существует явной схемы, определенной для глобалов. Можно создавать или уничтожать узлы глобала в любой момент. Они полностью динамические и не требуют предварительной декларации или схемы.
Обёртка для NoSQL решений
Некоторое время назад сайт TechRepublic опубликовал статью под названием "10 вещей, которые вы должны знать о базах данных NoSQL" (blogs.techrepublic.com.com/10things/?p=1772). Это перечисление 5 достоинств и 5 недостатков NoSQL баз данных. Если оценивать GT.M и Cache по этим десяти критериям, можно обнаружить, что они соответствуют всем перечисленным достоинствам, но, что более интересно, не имеют 4 из 5 их недостатков, чем другие NoSQL базы данных не могут похвастаться.
Достоинства
1. Линейное масштабирование:
Оба продукта, GT.M и Cache, в течение уже многих лет поддерживают масштабирование на несколько серверов и могут использовать при этом недорогое оборудование. В случае с Cache фирменная сетевая технология ECP (Enterprise Cache Protocol) позволяет создавать логическое отображение глобалов, в то время когда они могут быть физически распределены между несколькими серверами.
2. Много данных
Системы GT.M и Cache предназначены для поддержки и управления огромными объемами данных, далеко за пределами возможностей реляционных баз данных, но при этом обеспечивают высокую производительность.
3. До свидания, администраторы БД!
Интересно, что фирма InterSystems, производитель Cache, использует это преимущество в своей маркетинговой политике на протяжении многих лет. Есть истории систем на базе глобалов, которые функционировали без администрирования в течение десятилетий.
4. Экономичность
Оба продукта, GT.M и Cache, будут беcпроблемно работать на недорогих стандартных аппаратных платформах и извлекать из них максимальную производительность. Партнеры из здравоохранения в Массачусетсе поддерживали десятки тысяч интерактивных пользователей на протяжении 1980-х и 1990-х годов на сетевом кластере из сотен ПК с MSDOS и предшественнике Cache.
5. Гибкие модели данных
Это сама суть хранилища на глобалах, которая будет раскрыта в этой статье чуть ниже.
Недостатки
1. Зрелость
В отличие от новых NoSQL баз данных, GT.M и Cache имеют длинную родословную и выдающийся послужной список, поддерживающий большие и сложные базы данных в сложных условиях реальных бизнес-приложений. Это надежные и стабильные технологии, которые могут быть уверенно использованы в важных бизнес-приложениях.
2. Поддержка
GT.M активно используется в некоторых из крупнейших в мире банковских систем, в то время как Cache доминирует в здравоохранении. Одной из причин, по которым они используются в этих отраслях, является качество коммерческой поддержки, предоставляемой соответствующими поставщиками.
3. OLAP и бизнес-анализ
Оба продукта, GT.M и Cache, поддерживают подключения к инструментам SQL-бизнесаналитики. Также на протяжении многих лет они поддерживают доступ к SQL и не-SQL базам данных. В настоящее время InterSystems активно рекламирует продукт под названием DeepSee (intersystems.ru/deepsee), который предназначен именно для этой цели и является надстрокой над базой данных Cache.
4. Администрирование
Как GT.M, так и Cache просты в установке и обслуживании и часто используются в ситуациях, когда есть хоть один, если таковой вообще имеется, квалифицированный ИТ-специалист.
5. Специализация
Это действительно один из недостатков GT.M и Cache. Хотя число пользователей, в частности, для Cache, неуклонно растет, число квалифицированных специалистов, которые имеют опыт работы с GT.M и Cache очень мал, по сравнению с количеством специалистов реляционных СУБД.
Моделирование 4-х типов NoSQL баз данных с использованием глобалов
1) Ключ/Значение
Реализация хранилища типа ключ/значение с использованием глобалов тривиальна:
keyValueStore(key)=value
Например:
telephone("211-555-9012")="James, George"
telephone("617-555-1414")="Tweed, Rob"
Этого достаточно для создания простых ключ/значение хранилищ, но использование глобалов позволяет сохранять несколько атрибутов для каждого ключа. Например:
telephone(phoneNumber,"name")=value telephone(phoneNumber,"address")=value
Базы данных NoSQL обычно не предоставляют автоматических методов для индексации значений. Не делают этого и глобалы. Если необходимо получить доступ к данным с помощью другого ключа, то, соответственно, необходимо создать второй глобал с альтернативным свойством в качестве ключа. Для хранилища, приведенного выше, индексный глобал по имени может иметь следующую структуру:
nameIndex(name,phoneNumber)=""
Например:
nameIndex ("James, George", "211-555-9012")=""
nameIndex ("Tweed, Rob", "617-555-1414")=""
На диаграмме глобалы с данными и индексными значениями будет выглядеть следующим образом:
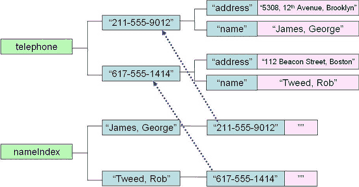
Индексный глобал позволяет организовать нам доступ к номерам телефонов по имени, в то время как основной глобал с данными предоставляет доступ к данным по телефонному номеру.
Очень важной и мощной характеристикой глобалов является то, что узлы глобалов сохраняются как отсортированный набор (как показано на рисунке выше).
Метод перебора узлов позволяет последовательно перебирать содержимое каждого глобала. Для того чтобы сделать телефонный справочник (с сортировкой по имени) на основе нашей модели, было бы достаточно пройти по узлам индексного глобала nameIndex и затем использовать метод get для доступа к данным глобала с телефонами.
Такой метод перебора узлов известен как функция order, которая представлена тем или иным способом в различных языках и фреймворках. Например, функция getNextSubscript клиента node-mdbm Node.js (github.com/robtweed/node-mdbm):
mdbm.getNextSubscript('nameIndex',['James, George'],
function(error,results) {});
в нашем случае вернет индекс узла глобала следующего за 'James, George':
{subscriptValue: 'Tweed, Rob'}
СУБД GT.M и Cache хорошо оптимизированы для обхода индексов подобным образом, и при наличии индексных глобалов поиск в данных будет очень быстрым.
2) Колоночные хранилища
Табличные или колоночные NoSQL базы данных, такие, как BigTable, Cassandra или Amazon SimpleDB, позволяют хранить данные в виде разреженных таблиц, а это означает, что каждая строка в таблице может иметь значение в некоторых, но не обязательно во всех, столбцах. База данных SimpleDB идет дальше и позволяет ячейке в столбце содержать более одного значения.
Схема реализации с помощью глобалов
columnStore(columnName, rowId)=value
Например:
user("dateOfBirth",3)="1987-01-23"
user("email",1)="[email protected]"
user("email",2)="[email protected]"
user("name",1)="Rob"
user("name",2)="George"
user("name",3)="John"
user("state",1)="MA"
user("state",2)="NY"
user("telephone",2)="211-555-4121"
Глобал, созданный выше, представляет следующую таблицу:

3) Документо-ориентированные
Документо-ориентированные NoSQL базы данных, такие, как CouchDB и MongoDB, хранят коллекции пар ключ/значение, а внутри них рекурсивно коллекции коллекций. Как правило, JSON, или JSON-подобные структуры используются для представления таких "документов".
Отображение документа или объекта в глобале: имена хранятся как индексы, а значения как значения. Для массивов используется числовой индекс для представления позиции в массиве. Рассмотрим, например, документ JSON:
{key:"value"}
Он может быть отражен в глобалах как:
document("key")="value"
Возьмем более сложный JSON документ:
{'name':'Rob', 'age':26
,'knows':['George','John','Chris']
,'medications':[
{'drug':'Zolmitripan'
,'dose':'5mg'
}
,{'drug':'Paracetamol'
,'dose':'500mg'
}
]
,'contact':{'eMail':'[email protected]'
,'address':{
'street':'112 Beacon Street'
,'city':'Boston'
}
,'telephone':'617-555-1212'
,'cell':'617-555-1761'}
,'sex':'Male'
}
И его хранение в глобале:
person("age")=26
person("contact","address", "city")="Boston"
person("contact","address", "street")="112 Beacon Street"
person("contact","cell")="617-555-1761"
person("contact", "eMail")="[email protected]"
person("contact", "telephone")="617-555-1212"
person("knows",1)="George"
person("knows",2)="John"
person("knows",3)="Chris"
person("medications",1, "drug")="Zolmitripan"
person("medications",1, "dose")="5mg"
person("medications",2, "drug")="Paracetamol"
person("medications",2, "dose")="500mg"
person("name")="Rob"
person("sex")="Male"
4) Графовые хранилища
Графовые NoSQL баз данных, такие, как Neo4j, используются для представления сложных сетевых связей в терминах узлов и связей между узлами (так называемый "ребер"), с парами ключ/значение добавляемых к узлам и связям.
Классический пример использования графовых баз данных - это представление социальных сетей. Рассмотрим следующий пример:
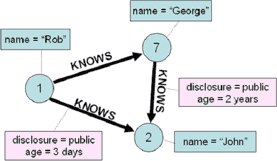
Он может быть представлен в глобалах как:
person(personId,"knows", personId)="" person(personId,"knows", personId,key)=value person(personId,"name")=name
Например:
person(1,"knows",2)="" person(1,"knows",2, "disclosure")="public" person(1,"knows",2,"age")="3 days" person(1,"knows",7)="" person(1,"name")="Rob" person(2,"name")="John" person(7,"knows",2)="" person(7,"knows",2, "disclosure")="public" person(7,"knows",2,"age")="2 years" person(7,"name")="George"
Обобщенная схема хранения для графовых БД может выглядеть, например, так:
node(nodeType,nodeId)="" node(nodeType,nodeId, attribute)=attributeValue edge(edgeType,fromNodeId, toNodeId)="" edge(edgeType,fromNodeId, toNodeId,attribute)= attributeValue edgeReverse(edgeType, toNodeId,fromNodeId)=""
5) Другие модели данных
Область применения глобалов не ограничивается только NoSQL моделями. Они также могут быть использованы для моделирования других типов баз данных:
- XML DOM/XML базы данных. Продукт EWD (www.mgateway.com/ewd.html) по своей сути является реализацией XML DOM на основе глобалов. По существу, это графовая структура, которая представляет узлы (и связанные с ними типы) и отношения между ними (например, FirstChild, LastChild, NextSibling, родителей и т.д.). В сущности, EWD позволяет GT.M и Cache вести себя как native-XML базе данных.
- Реляционные таблицы. Оба продукта, GT.M и Cache, моделируют реляционные таблицы на глобалах (в случае GT.M это осуществляется с помощью дополнительного продукта, известного как PIP, а Cache имеет встроенную поддержку реляционных таблиц). В обоих случаях можно использовать SQL-запросы как внутри продуктов, так и через стандартные инструменты сторонних производителей.
- Хранилища хранимых объектов. Cache в этом случае идет еще дальше и предоставляет прямое соответствие между сохраненными объектами и реляционными таблицами. В последних версиях Cache представлена новая технология Java eXTreme (www.intersystems.com/java), значительно расширяющая возможности Java-разработчиков по сохранению объектов и данных.
Заключение
СУБД GT.M и Cache могут поддерживать любые или все модели баз данных, описанных выше, причем одновременно, если потребуется. То есть можно иметь аналоги Redis, CouchDB, SimpleDB, Neo4j, MySQL и XML хранилищ, работающие в одной и той же базе данных в одно и то же время.
GT.M и Cache имеют интерфейсы для языков программирования и фреймворков, включая Python, Java, .NET и Node.js, что делает их идеальными кандидатами для NoSQL решений.
Как GT.M, так и Cache в результате являются идеальными кандидатами для предприятий, которым требуются технологии NoSQL, при дополнительных требованиях к зрелости, прочности и надежности. Хотя оба продукта имеют коммерческую лицензию и работают на широком спектре оборудования и операционных систем, GT.M особенно интересен тем, что доступен как Open Source продукт при запуске на платформе GNU/Linux.
Подготовил Олег ДМИТРОВИЧ
По материалам статьи Роба Твида и Джорджа Джеймса www.mgateway.com/docs/universalNoSQL.pdf










