В рамках прохождения курса «Распределённое программирование» на Coursera встретился с интересным заданием, которое мне понравилось простотой и лаконичностью его решения, которым я и решил поделиться.
Итак, задание: реализовать алгоритм размытия изображения, вычисления должны распараллеливаться. Задача не искусственно-обучающая: функцию размытия сейчас можно найти в каждом первом приложении, предназначенном для работы с графикой.
Реализацию я буду приводить на Scala. Язык местами непростой, но по итогу код по ясности выражения мыслей может конкурировать с псевдокодом. Если какая-либо конструкция не будет понятна, пишите в комментарии – перепишу на Java.
Итак, приступим.
Схема RGBA – классический вариант представления цвета. Пиксель представляется четырьмя значениями (от 0 до 255): red, green, blue – соответствующие цвета, alpha – прозрачность. Соответственно, нам нужен тип для представления пикселя и функции, которые бы позволяли извлекать каждую составляющую из RGBA-типа. Не забываем и об «упаковке» всех составляющих в одно RGBA-значение.
Пиксель представим типом RGBA, который, в свою очередь, является 32-битным числом.
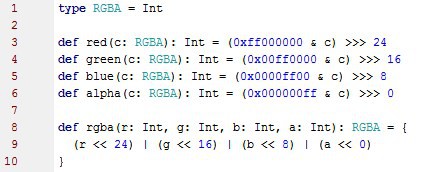
Начало положено.
Далее нам нужна реализация изображения. Изображение состоит из пикселей типа RGBA. Нужно реализовать навигацию по изображению с помощью системы координат. По сути, все, что нам нужно – это данные о ширине и высоте изображения, а также функции обновления и получения отдельного пикселя.

Итак, мы подобрались к самому главному – к размытию. Размытие будем выполнять самым незамысловатым способом: вычислением средних значений всех каналов цветов всех соседствующих пикселей. Степень размытия контролируется значением радиуса. Радиус – это количество пикселей, которое мы «захватываем» с каждой стороны целевого пикселя для расчета средних значений.
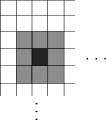
То есть при единичном радиусе будут рассчитываться средние значения десяти пикселей (9 соседних + целевой). При реализации метода нужно не забыть, что нельзя допустить выхода за границы изображения. Приступим к реализации.
Начнем с сигнатуры метода. Метод должен принимать изображение, координаты точки, которую нужно размыть, и радиус. Возвращаем новый пиксель типа RGBA.
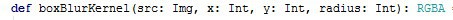
Для лаконичности заведем тип для хранения координат пикселя.
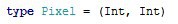
Далее нам нужно вычислить координаты прямоугольника, все пиксели внутри которого будут использоваться для вычисления среднего значения. С одной стороны верхняя левая точка этого прямоугольника ограничивается границами изображения, с другой – нашей целевой точкой. Нижняя правая точка также ограничивается сначала целевой точкой и затем границами изображениям, соответственно. Для «обрезания» значений реализуем метод clamp.

С учетом вышеуказанных ограничений теперь мы можем найти координаты прямоугольника.

Заведем 4 счетчика-аккумулятора для компонентов цвета и один общий счетчик для того, чтобы знать, сколько, собственно, пикселей мы обошли.

Осталось совсем немного. Построчно итерируемся по вычисленному прямоугольнику, обновляя аккумуляторы и счетчик.

Объединяем все воедино, возвращая новый RGBA-пиксель.

Теперь немного размышлений о возможности распараллелить задачу.
Вычисление размытия отдельного пикселя – очень легкая задача, поэтому идею о ее решении в отдельном потоке можно отбросить сразу. Нужно бить изображения на сектора. Но на какое количество и каким образом? На первый вопрос можно ответить исходя из того, что даже очень крутой суперкомпьютер не имеет бесконечного числа вычислительных ядер. То есть нужно исходить из возможностей имеющихся ресурсов. Если у нас восьмиядерная машина – можно справедливо предположить, что, в общем случае, задача, не несущая в себе больших накладных расходов на совмещение результатов вычисления подзадач, вычисления которой происходят в 8 потоках, решится быстрее, чем решение ее в одном потоке. Делаем вывод, что для пользователя важно предоставить возможность самому выбирать количество потоков в соответствии с имеющимися у него ресурсами. Таким образом, нам нужно разбить изображение на N примерно одинаковых секторов, где N – количество потоков для решения, и потом параллельно размыть все эти сектора.
Как разбивать изображение? Зависит от реализации самого изображения. У нас реализован самый примитивный вариант: одномерный массив пикселей. Таким образом, даже если в подзадачах будут перечисляться отдельные случайные пиксели, производительность от этого почти никак не пострадает. Можно сфокусировать на лаконичности кода. Самый наивный и просто реализуемый вариант – это размытие в одной подзадаче определенного диапазона столбцов или строк. Приступим.
Метод blur принимает два изображения (исходное и целевое), радиус размытия, а также диапазон столбцов (from и to). Итерируемся сначала по столбцам, затем по отдельным пикселям, обновляя целевое изображение полученными размытыми пикселями.

Осталось запустить задачи на исполнение. Я опустил реализацию генерации диапазонов для подзадач ввиду ее тривиальности. Так же не буду демонстрировать код, реализующий диспетчеризацию задач, так как это никоим образом не относится к сегодняшней теме. Для каждого диапазона столбцов запускаем новую задачу (task). Затем же просто ожидаем окончание всех вычислений.

На этом реализация алгоритма закончена. Можно поэкспериментировать с количеством потоков. В этом случае очень хорошо себя показал hyper-threading от Intel (каждое ядро поддерживает 2 логических потока). В моем случае (у процессора 4 физических ядра) 8 потоков обрабатывали задачу на 40-50% быстрее, чем 4. А вот дальнейшее увеличение числа потоков ощутимого ускорения не дали.
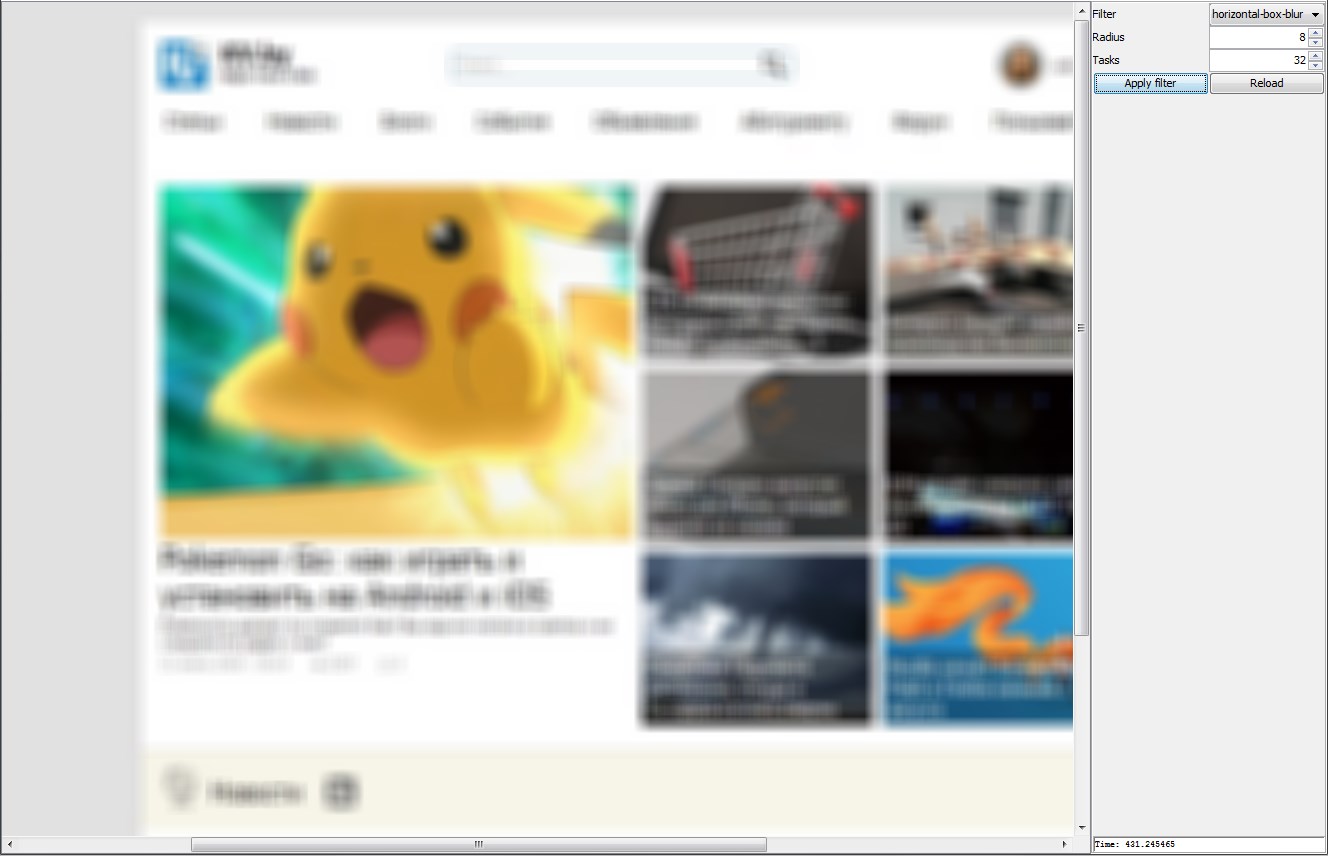
Спасибо, что дочитали.
Антон Ковалевский











Комментарии
Отличная публикация! Спасибо, Антон!
Гхм. Размытие усреднением -- общеизвестная вещь. Что-то я не уловил особой новизны. В алгоритме, что ли? Стар, наверное. Но ведь прочёл!
Вообще же для блюринга существует уйма алгоритмов.
В данной статье мне было интересно, как выглядит Scala. Так и не понял преимущества перед "плюсами". Олдфаг, значит.
Но по-любому -- моё спасибо автору.
Здравствуйте, если не сложно напишите на Java