Метод распределённого вычисления можно представить как разбиение задачи, которую должен выполнять один компьютер, на несколько задач меньшего размера, выполняемых на нескольких компьютерах. Пусть одна из подзадач имеет максимальное время выполнения tmax среди всех подзадач, но всё же это время в общем случае меньше, чем время T, которое компьютер потратил бы на решение совокупной задачи. Таким образом, распределённое вычисление увеличивает скорость решения задачи пропорционально T/tmax, хотя сумма времени, потраченного на всех компьютерах, может оказаться больше, чем время, которое потратил бы один компьютер.
Актуальность распределённого вычисления, таким образом, связана с тем, что современный человек располагает ресурсами, но не располагает временем, но эта статья не будет касаться философских тем, поскольку мы собираемся затронуть практическую задачу, которая непосредственно вытекает из потребности воспользоваться методом распределённого вычисления. Речь будет идти о том, каким образом программа, исполняемая одним компьютером, может быть разбита на меньшие программы, исполняемые на нескольких компьютерах.
Для того, чтобы решить поставленную задачу представим программу как последовательность строк, содержащих входные данные и результаты вычислений. Данные, являющиеся результатами вычислений, получаются из других данных путём применения к ним операций некоторого конечного множества. Чтобы описать корректное поведение программы, будем полагать, что все данные, из которых посредством применения операций был получен рассматриваемый результат вычислений, содержатся в строках, предшествующих строке с этим результатом. Для краткости изложения, не теряя сути, будем считать, что результаты вычислений, к которым в дальнейшем не применяются рассматриваемые операции, полностью соответствуют тому интересующему набору данных, которые должны быть посчитаны на одном, либо нескольких компьютерах.
Указанное описание программы удобно перевести на язык математических формул. Рассмотрим для простоты следующие операции - умножение (a*b), прибавление 2 (a+2), возведение в степень 2 (a^2) и разность (a-b). Назовём программой последовательность строк формул, такую, что для формулы каждой строки все подформулы предыдущего уровня ("-1"), если они существуют, содержатся в предыдущих строках. Для понимания смысла подформул уровня "-1" обратимся к формуле (a+b^2)*a. Подформулами уровня "-1" для неё являются только 2 формулы - (a+b^2), a. Подформулы b, b^2 сюда не отнесены, так как они требуют совершения больше 1 операции для перехода в исходную формулу.
Рассмотрим следующий пример программы:
1) a
2) b
3) c
4) a+2 [1]
5) (a+2)*b [4,2]
6) c*b [3,2]
7) (c*b)-(a+2) [6,4]
8) c^2 [3]
9) (c^2)*((a+2)*b) [8,5]
10) c*a [3,1]
11) (c*a)-b [10,2]
12) (c*b)-(c*a) [6,10]
Мы можем убедиться в том, что приведённая последовательность строк формул действительно является программой, поскольку для каждой встречающейся формулы её подформулы уровня "‑1", если они имеются, содержатся в строках с меньшим номером, чем номер строки исходной формулы (номера строк подформул обозначены в квадратных скобках).
Далее мы будем считать, что формулы, имеющие подформулы, но не являющиеся сами таковыми, соответствуют интересующему набору данных программы. Наша задача в простом случае заключается в том, чтобы по списку исходной программы с набором из нескольких интересующих данных получать программы, содержащие лишь одно интересующее данные. Как мы убедимся в этом дальше, такая процедура позволит уменьшить количество строк любой из полученных программ в сравнении с исходным количеством в 12 строк. Это и соответствует тому уменьшению времени работы компьютера, о котором шла речь вначале.
Чтобы добиться разбиения программы на программы меньшего уровня, выделим в ней, прежде всего, те формулы, которые имеют подформулы, но подформулами не являются. Очевидно, это такие формулы, чьи номера строк не встречались среди всех квадратных скобок, однако в их строке - квадратные скобки содержатся. Такие формулы в нашем примере размещены в строках 7, 9, 11 и 12. Определим далее граф G программы как ориентированный граф, вершинами которого являются строки программы, а дуга (X,Y) существует тогда и только тогда, когда в строке Y содержится некоторая формула A, а в строке X - подформула A уровня "-1". Граф рассмотренной программы будет выглядеть следующим образом:
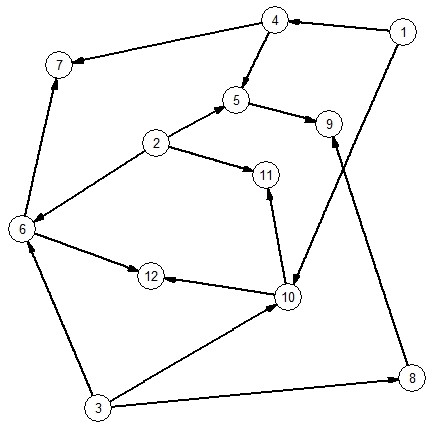
Рисунок 1. Граф исходной программы
Далее нам следует рассмотреть граф, порождённый вершиной N, который является ни чем иным как графом, порождённым вершиной N, а также всеми вершинами N1, N2, … , такими, что существуют дуги (N1,N), (N2,N), …, а также всеми вершинами N11, N12, …, N21, N22, такими, что существуют дуги (N11,N1), (N12,N1), …, (N21,N2), (N22,N2), … и т.д. Граф, порождённый N, таким образом, соответствует максимальному подграфу, образованному движением из N против направления дуг.
Следующий шаг непосредственно ведёт нас к тому, чтобы задать программы, на которые разбивается исходная программа при распределённом вычислении, а именно - достаточно рассмотреть все графы, порождённые строками тех формул, которые не являются подформулами, но содержат подформулы. В нашем случае - графы, порождённые вершинами 7, 9, 11 и 12. Обратимся к их изображению, чтобы понять, чем являются порождённые графы:
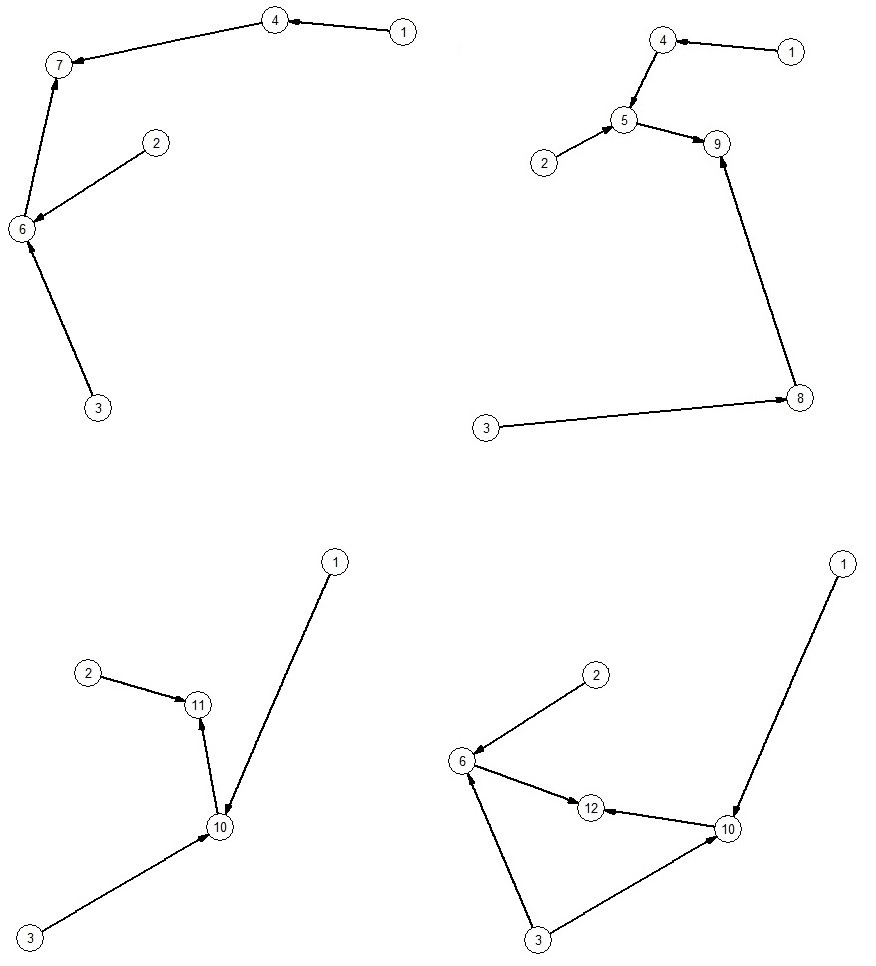
Рисунок 2. Графы, порождённые вершинами 7 (ВЛ), 9 (ВП), 11 (НЛ), 12 (НП)
Дальнейшая задача сводится непосредственно к составлению программ, для чего каждому полученному графу поставим в соответствие возрастающий список строк исходной программы, чьи номера равны вершинам рассматриваемого графа.
Программа, вычисляющая 7 ((c*b)-(a+2)):
1) a
2) b
3) c
4) a+2 [1]
6) c*b [3,2]
7) (c*b)-(a+2) [6,4]
Программа, вычисляющая 9 ((c^2)*((a+2)*b)):
1) a
2) b
3) c
4) a+2 [1]
5) (a+2)*b [4,2]
8) c^2 [3]
9) (c^2)*((a+2)*b) [8,5]
Программа, вычисляющая 10 ((c*a)-b):
1) a
2) b
3) c
10) c*a [3,1]
11) (c*a)-b [10,2]
Программа, вычисляющая 12 ((c*b)-(c*a)):
1) a
2) b
3) c
6) c*b [3,2]
10) c*a [3,1]
12) (c*b)-(c*a) [6,10]
Как нетрудно убедиться, нами получены программы в том смысле, который мы определили вначале (остаётся переименовать строки и соответствующие ссылки). Кроме того, все полученные программы и только они - определяют данные, которые нас интересовали, при этом работая лишь над одним из них. Таким образом, нам удалось сократить время работы исходной программы с 12 до 7 (максимальное количество строк, соответствующее программе для 9), то есть увеличить скорость вычисления примерно в 1,714 раз. Мы также можем посчитать, что общий ресурс времени, затрачиваемый на вычисления, увеличился с 12 до 24 (сумма строк полученных программ), то есть возрос ровно в 2 раза. Это говорит нам о том, что время иногда является деньгами в большей мере, чем деньгами являются сами деньги. В связи с этим стоит пожелать читателю больше свободного времени.
Эльмар Гусейнов















Комментарии
Ну вообще-то всё значительно сложнее, чем это представил а статье автор. Дело во времени получения готовности промежуточных результатов. Поэтому рёбра графов в распределённых задачах имеют вероятностные веса, да не простые, а случайные внутри некоторых диапазонов. Впрочем, полагаю, что автор об этом знает и просто не хотел излишне грузить читателя.
Если подумать, то напрашивается и возможность выбрать наиболее оптимальное распараллеливание, в случаях, когда много идентичных или схожих задач - с помощью тех же графов:-).