Возможность легкого копирования информации, представленной в электронном виде, породила множество проблем, связанных с нарушением авторских прав. В бумажных и электронных изданиях часто можно встретить публикации об очередном противостоянии пиратов и владельцев авторских прав на распространяемые этими пиратами произведения. Как правило, в таких случаях единственным (но не всегда действенным) способом улаживания конфликтов являются судебные разбирательства. При этом пострадавшей стороне добыть необходимые доказательства часто не составляет большого труда, поскольку пираты редко пытаются скрыть тот факт, что распространяемые ими произведения не являются лицензионными. В данной статье рассматриваются методы, позволяющие обнаружить и доказать факт нарушения авторских прав в случаях, когда целью противозаконных действий является разработка программного обеспечения, содержащего в себе нелегально заимствованные фрагменты чужих программ.
Необходимо сказать, что, кроме описанных в статье, существует и множество других методов. Также ничто не мешает разработать собственные приемы, направленные на выявление плагиата.
Анализ характеристик программы
Любая программа имеет определенную иерархию структур, которые могут быть выявлены, измерены и использованы в качестве характеристик программы. Применительно к доказательству факта заимствования эти характеристики должны слабо меняться в случае модификации программы или включения фрагментов одной программы в другую. Имена процедур и переменных, текстовые строки и тому подобное могут быть легко изменены злоумышленником и поэтому не должны использоваться для получения характеристик. Для этой цели лучше подойдет последовательность операторов программы, поскольку модификация этой последовательности требует глубокого понимания логики функционирования программы и является очень трудоемким процессом.
Ознакомление с анализом характеристик программы проведем на примерах анализа частот появления операторов и размещения операторов в теле программы.
Рассмотрим частоты появления операторов в определенном фрагменте программы. Частота определяется как количество появлений конкретного оператора, деленное на количество появлений всех операторов. Частоты можно изобразить в виде гистограммы. На рисунке 1 изображена гистограмма некоторой программы. На абсциссе отложены порядковые номера операторов, а на ординате - частоты (в процентах) появлений этих операторов.
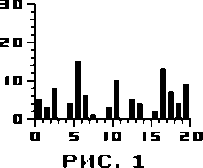
При маскировке нелегально заимствованного фрагмента злоумышленник может изменить некоторые операторы и добавить новые, но в целом изменения, вероятно, будут малы, и ожидается, что распределение частот останется практически тем же. Конечно, близкие значения частот во фрагментах различных программ еще не являются доказательством факта заимствования, но зато дают повод это подозревать.
Перейдем теперь к анализу размещения операторов в теле программы. Возьмем две последовательности операторов и сравним их для того, чтобы получить взаимную корреляцию операторов этих последовательностей.
Сравнение будет проводиться следующим образом. Первый оператор одной последовательности сравнивается с первым оператором другой последовательности. Если операторы одинаковы, то счетчик совпадений увеличивается на единицу. Далее берутся вторые операторы, сравниваются, и при совпадении счетчик опять инкрементируется. Этот процесс продолжается до тех пор, пока не будут выбраны все операторы. В том случае, когда длины последовательностей различны, сравнение производится по длине более короткой последовательности.
После того, как все операторы выбраны, количество совпадений запоминается, а затем производится повторное сравнение, но перед этим более короткая последовательность сдвигается так, что ее первый оператор сравнивается со вторым оператором более длинной, второй - с третьим, и так далее. Когда будет получено еще одно число, характеризующее количество совпадений, оно также запоминается, одна из последовательностей опять сдвигается, опять производится сравнение, и так до тех пор, пока более короткая последовательность не сдвинется циклически столько раз, сколько операторов в более длинной. Полученная информация изображается в виде гистограммы, на абсциссе которой откладывается величина смещения одной последовательности операторов относительно другой, а на ординате - количество совпадений операторов при таком смещении.
На рисунке 2 представлена гистограмма взаимной корреляции двух коротких программ.
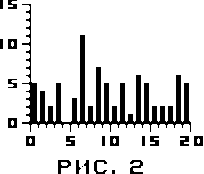
Пик, наблюдаемый на седьмой позиции, возник из-за того, что в этих программах встречаются одинаковые фрагменты. Кроме закономерной, может возникнуть заметная случайная корреляция, поэтому каждый случай высокого значения корреляции следует анализировать другими методами.
Как уже отмечалось, близкие значения характеристик двух различных программ не означают, что в одной программе присутствуют фрагменты другой. Данное обстоятельство является недостатком описанного метода. Однако необходимо отметить, что он позволяет легко автоматизировать процесс выявления подозрительных участков программного кода и при использовании совместно с другими методами может дать значительные результаты.
Анализ стиля программирования
При рассмотрении стиля программирования часто используется термин "родимые пятна" ("birthmarks"), введенный в употребление в Британском обществе вычислительной техники (British Computer Society) для обозначения особенностей, которые присущи стадии разработки программы и которые становятся в дальнейшем неотъемлемой частью этой программы. Признано, что родимые пятна существуют объективно. Это обстоятельство позволяет использовать анализ стиля программирования для доказательства факта заимствования.
Значительное количество родимых пятен появляется в программе благодаря индивидуальным особенностям программирования, присущим каждому программисту. В качестве примеров таких особенностей можно назвать заготовки, наработанные программистом в процессе работы, части кода из более ранних версий программы, фрагменты, написанные при разработке программы, но не удаленные после того, как они стали ненужными.
В качестве родимых пятен также рассматриваются ошибки. Воспроизведение ошибки может служить доказательством заимствования, поскольку маловероятно, чтобы один человек самостоятельно и независимо повторил ту же ошибку, что и другой. Следует отметить, что некоторые ошибки могут быть присущи разным людям. Это обстоятельство было выявлено в целом ряде новых технологий, в основе которых заложены трудноразрешимые концепции. При использовании этих технологий разработчикам оказываются свойственны однотипные ошибки, однако ясно, что если ошибка очевидна, то маловероятно, чтобы другие могли ее повторить.
Стилевые особенности не очевидны автору из-за того, что это его собственные неконтролируемые особенности, поэтому для облегчения выявления плагиата можно вводить в программу дополнительные родимые пятна. Это могут быть ошибки, которые не сказываются на работоспособности программы, или избыточный код, который может включаться с намерением ввести злоумышленника в заблуждение (в частности, для того, чтобы заставить его выполнять лишнюю работу по выяснению, является ли данный код действительно избыточным или же он предназначен для вызова в некоторых исключительных ситуациях).
Анализ стиля программирования является эффективным методом, поскольку устранение стилевых особенностей приводит к переписыванию программы и выявлению неэффективных частей программы, которые могли появиться из-за использования программистом не самых эффективных алгоритмов. В то же время, если программа, в которой использована часть исходного текста другой программы, представлена в машинном коде, то процедура поиска родимых пятен может стать очень сложной. Это обусловлено тем, что компиляторы устраняют избыточность кода и сглаживают стилевые особенности.
Завершая часть, посвященную анализу стиля программирования, следует отметить одно немаловажное преимущество описанного метода, а именно то, что с его помощью можно установить авторство фрагмента программы, даже если разработка и распространение программы были выполнены до принятия мер по защите от нелегального копирования.
Анализ идентификационных меток
Термином "идентификационная метка" ("fingerprint") в этой статье будет обозначаться информация, кодирующая некоторое удостоверение авторства способом, достаточно невероятным, чтобы его распознать случайно, и которая служит доказательством того, что удостоверение авторства действительно присутствует.
Эффективность использования идентификационных меток обусловлена неопределенностью и неожиданностью их расположения. В некоторых случаях имеет смысл информировать о том, что они присутствуют. Тогда, обнаружив часть меток, злоумышленник не будет уверен в том, что нашел их все, и это может заставить его отказаться от попыток заимствования. Конечно, злоумышленник мог бы в принципе ввести дополнительные идентификационные метки, чтобы запутать автора программы в случае судебного разбирательства, но сохранение исходного текста должно устранить любые сомнения по отношению к настоящему автору.
Разрабатывая идентификационные метки, необходимо помнить, что они хорошо защищены от модификации или удаления только в том случае, если неизвестен принцип их построения. Разглашение этого принципа лишает смысла его использование, по этой причине описанный в следующем абзаце пример не рекомендуется использовать на практике.
В части, посвященной идентификации программного кода на основе анализа стилевых особенностей программирования, был упомянут такой тип родимых пятен, как преднамеренные ошибки. При этом предполагалось, что они не могут появиться в других программах, если только не скопированы с оригинала. Ошибки могут использоваться для кодирования удостоверения авторства. К примеру, код программы, выдающий на выходе последовательность чисел, может модифицировать эти числа так, чтобы две последние цифры на пределе округления кодировали буквы алфавита и таким образом неявно выводили, скажем, фамилию разработчика данного кода. Ясно, что при этом вносимые ошибки не должны искажать суть выполняемых операций.
Если введение искажений недопустимо, то можно действовать по-другому. Поскольку изменение порядка следования соседних и независимых друг от друга операторов не влияет на работоспособность программы, то это обстоятельство можно использовать для создания идентификационных меток. Конечно же, разработать метку, связанную с последовательностью операторов, очень сложно, поэтому можно просто включить в программу код, который никогда не будет выполняться. Однако, такое размещение меток может принести плоды лишь в том случае, если при заимствовании фрагментов программы злоумышленник не будет досконально разбираться в их работе.
В заключение необходимо сказать еще несколько слов об удостоверении авторства. Знание злоумышленником имени автора, названия компании или другой информации подобного рода является мощным ключом к проблеме выявления и удаления идентификационных меток. По этой причине информацию, содержащуюся в метках, рекомендуется шифровать. Однако не стоит увлекаться - чем сложнее процедура шифрования, тем меньше доверия к зашифрованной метке, поскольку с увеличением сложности алгоритма шифрования может увеличиваться возможность подтасовки расшифрованных данных.
Сергей ИВАНЧЕГЛО,
[email protected]











Комментарии
What about of the practical application of your excellent methods?I'd like to find a use of my mathematical methods in programming and levy the "taxes" from the violators of my copyright.
Yours sincerely,Yuri