Alibaba представила QwenLong-L1 — новую архитектуру больших языковых моделей (LLM), способную эффективно обрабатывать исключительно длинные входные данные. Это открывает широкие возможности для корпоративных приложений, работающих с масштабными документами: от подробных отчётов и финансовой отчётности до сложных юридических контрактов.
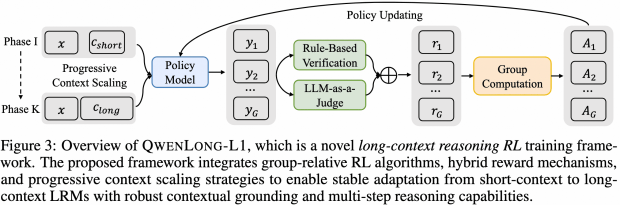
Преодолевая ограничение большинства существующих моделей, которые испытывают сложности с текстами, превышающими 4000 токенов, QwenLong-L1 использует многоэтапный подход к обучению. Он включает контролируемую тонкую настройку на примерах длинных контекстов, поэтапное обучение с подкреплением (RL) с постепенным увеличением длины входных данных и финальный этап обучения на сложных примерах, стимулирующий освоение самых трудных задач.
Ключевым элементом является гибридная система вознаграждения, сочетающая строгую проверку на основе правил и оценку другой LLM, что позволяет учитывать нюансы и различные варианты правильных ответов в длинных текстах.
Результаты тестирования на семи наборах данных DocQA впечатляют: QwenLong-L1-32B показала производительность, сравнимую с Anthropic’s Claude-3.7 Sonnet Thinking, и превзошла OpenAI o3-mini и Qwen3-235B-A22B. Более компактная версия, QwenLong-L1-14B, опередила Google Gemini 2.0 Flash Thinking и Qwen3-32B.










