Как автоматически распознают порно современные системы фильтрации контента
Ни для кого не секрет, что порно существует. Само явление старо как мир и из века в век развивается наравне с человечеством, становясь то более доступным, то уходя в подполье под запреты. В некоторых странах порнография узаконена, в некоторых за неё можно в лучшем случае угодить в тюрьму, а может, и вовсе проститься с жизнью. Учёные до хрипоты спорят, проводя исследования, чего больше приносит порнография - пользы или вреда. Одно исследование может утверждать, что благодаря порнографии снижается количество изнасилований. Другое исследование иногда, даже на основе тех же самых данных, представляет совершенно противоположные выводы. Так что же такое порнография - благо или зло? Предоставим это решать философам, политикам, домохозяйкам... да кому угодно. Сегодня я хочу взглянуть не на проблему порно как явления, а на способы его автоматического определения и отлова.
Посудите сами, порно не получится истребить. Оно было и будет. Но вряд ли найдётся хоть один родитель, который был бы рад увидеть своего малолетнего ребёнка за просмотром какого-нибудь очередного бестселлера от студии "Private". Поэтому, несомненно, важной задачей является именно отлов порноконтента ещё на периоде загрузки его на файлообменник. Если ребёнку не дать возможности просмотра, то мало кто полезет искать его самостоятельно. Ну и стоит ли напоминать вам, что в нашей стране производство, хранение и распространение порнографии уголовно наказуемы? Так как же могут обезопасить себя владельцы файлообменных сервисов от недобросовестных пользователей, которые вопреки правилам грузят запрещённый контент?
Самым надёжным решением и в то же время самым низкопроизводительным является армия модераторов, которая вручную будет просматривать каждый загруженный видеофайл. Вы уже чувствуете дух маразма? Поэтому не будем задерживаться на этом способе - минусы очевидны. Армию модераторов нужно кормить, платить зарплату, нет 100% гарантии от ошибок, вызванных человеческим фактором. Зайдём с другой стороны. Пусть всё делает автоматика. В этом подходе минусы также очевидны.
Самым надёжным решением и в то же время самым низкопроизводительным является армия модераторов, которая вручную будет просматривать каждый загруженный видеофайл.
В итоге самым разумным решением будет использование комбинированного подхода. Если взяться за описание его модели, то получится примерно следующее:
- есть софт, который каким-то образом производит отбор роликов с запрещённым содержанием;
- есть SecurityOfficer, к которому попадает уже отобранный автоматикой контент. Этот человек выносит окончательное решение по ролику (ведь автоматика могла и ошибиться).
И если с работой SecurityOfficer всё понятно, то к софту есть вопросы. Как научить машину определять порно? Этому вопросу и посвятим нашу статью. В материале я буду опираться на существующий порнофильтр Licenzero.
Основные подходы
При анализе порноматериалов существуют четыре подхода, которые позволяют с максимальной вероятностью определить принадлежность ролика к необходимому нам классу:
- цвет;
- содержание кадра;
- характер движения;
- звук (куда ж без него).
Цвет
Секрет успеха кроется в обучении будущего порнофильтра. Для этого важно понимать, что по сути надо решить только две задачи:
- какой цвет кожи называть "цветом кожи";
- классифицировать порноролики по цвету кожи.
Для решения первой задачи необходим начальный материал. Он отбирается вручную. Картинки, скриншоты из видео и т.д. Так сказать, проявите фантазию. Этот материал не обязательно должен быть порнографическим, ведь кожа в обоих случаях одинакова.
Затем нужно получить координаты точек, классифицированных как человеческая кожа. Вот один из вариантов решения:

С помощью самодельной программы человек вручную закрашивает все места, где кожи нет. Для большей точности выделения можно сделать различный размер кисти, которой производится выделение. Также можно подойти с другой стороны и выделять области с кожей. Выбор за вами.
Тем временем координаты миллионов точек (в RGB) получены и встаёт новая проблема: проблема выбора цветовой модели, в которой будут рассматриваться полученные точки. Что выбрать: RGB, LAB, HSV, YСbCr...? В рассматриваемом порнофильтре выбор пал на YСbCr. Не в последнюю очередь потому, что поскольку предстояло классифицировать именно по цвету, то можно было отбросить "серую" компоненту яркости Y.
Так выглядят точки картинок на шкале Сb:
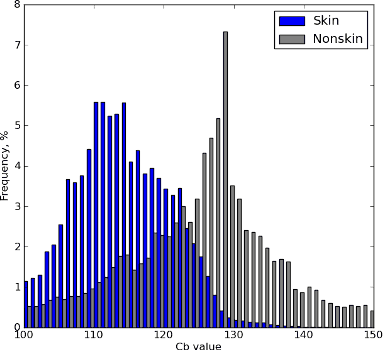
И на шкале Сr:
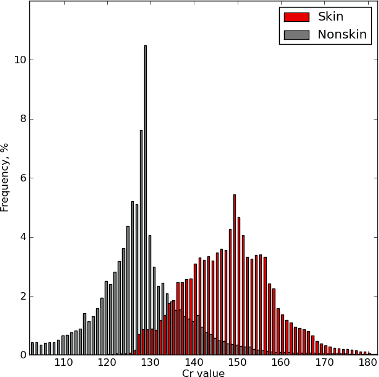
Заметно, что по этим двум координатам можно выделить пиксели кожи. Вот как выглядит вероятность (по нашим данным) того, что некоторая точка с координатами Cb и Cr является кожей:
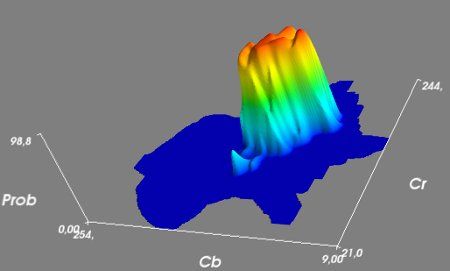
Там, где синий цвет - вероятность равна 0%, там, где красный - 100%. Эта горка говорит о том, что, выбрав, например, 50% в качестве порога для классификации кожи, легко можно отделить цвет кожи (в координатах Cb и Cr) от всего другого цвета.
Для целей классификации можно использовать не SVM, а просто определить прямоугольную область, оптимально классифицирующую пикселы кожи. То есть, такой псевдо-SVM с четырьмя опорными векторами.
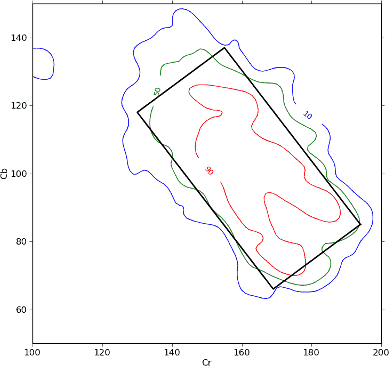
Черная линия - и есть этот псевдоSVM. Зеленая линия - вероятность в 50% того, что точка на этой кривой относится к коже (красная: 90%, синяя: 10%). То есть, все точки с координатами Cb и Cr, которые попадают внутрь черного прямоугольника, являются пикселами кожи.
Думаю, хватит теоретических выкладок. Пора взглянуть, как такая система работает на практике:
Систему можно и дальше улучшать, но зачем? Такого анализа достаточно, чтобы перейти к решению более интересной задачи: к классификации по цвету кожи.
Классификация по цвету кожи
Теперь программа знает, что именно считать кожей. Пора научить её отличать "порно" от "не порно". Поскольку, в основном, нужно обрабатывать видеоданные, то от цветового пространства YCbCr лучше перейти к YUV (по сути, это одно и то же). C YUV работать в данном случае удобно, так как не нужно не только перекодировать сырое видео, но и пар (U, V) получается в два раза меньше, чем точек в кадре (если видео в формате yuv420p). Выгода, как говорится, налицо.
А с самой классификацией всё обстоит гораздо проще, чем вы думаете. Если объяснять "на пальцах", то в порно люди голые, а в остальных видео одетые (конечно, многие из читателей тут же могут опровергнуть меня и сказать, что в категорию "порно" запросто попадёт и Hustler, и семейное видео с отдыха в Турции. Всё так. И именно поэтому классификация по цвету кожи - лишь один четырёх методов, по которым будет выноситься окончательный вердикт).
В категорию "порно" запросто попадёт и Hustler, и семейное видео с отдыха в Турции. И именно поэтому классификация по цвету кожи - лишь один четырёх методов, по которым будет выноситься окончательный вердикт.
Таким образом, нужно посчитать долю цвета кожи в порно и непорно роликах (то есть количество "кожаных" пикселов разделить на общее количество пикселов в ролике). Результат представлен ниже:
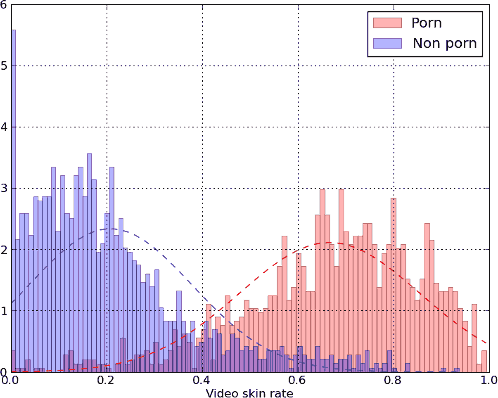
Это гистограммы распределения роликов. По оси Y - количество роликов, по оси X - доля пикселов кожи в ролике. Пунктирными линиями показаны графики плотности распределения.
Если измерять долю пикселов кожи не в целых роликах, а в порно и непорно фрагментах, а такие фрагменты стоит предварительно нарезать вручную, то результаты будут еще лучше.
В итоге, детектор цвета кожи возвращает вероятность того, что фрагмент является порнографическим. И эта вероятность просто является функцией от доли пикселов кожи во фрагменте. Функция приблизительно такая:
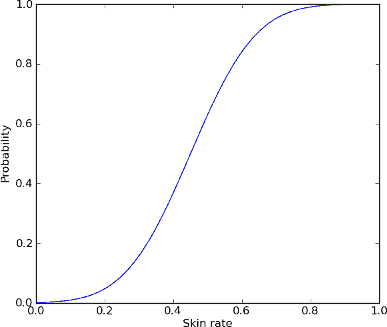
Итак, подводя черту под первым подходом в определении порно, резюмируем его основные принципы:
- считаем количество пикселов кожи во всех кадрах фрагмента;
- делим на общее число пикселов кожи во всех кадрах фрагмента - получаем долю пикселов кожи;
- в зависимости от доли пикселов кожи, получаем значение вероятности того, что фрагмент - порнографический;
- используем данную вероятность наравне с остальными для итоговой классификации фрагмента и целого ролика.
Содержание кадра
При поиске порнографии нельзя оставить без внимания и отдельные кадры. Нужно поискать что-нибудь и там. Для извлечения полезной информации непосредственно из кадров в рассматриваемом фильтре используют Bag of Visual Words. То есть сначала определяются "визуальные слова" - фрагменты или сэмплы, которые лучше всего характеризуют кадры с порно и без. Получается такой набор визуальных слов. А затем при классификации детектор по наличию тех или иных слов в картинке дает оценку порнографичности данного кадра.
Для извлечения полезной информации непосредственно из кадров в рассматриваемом фильтре используют Bag of Visual Words.
Но этот подход не единственный. В кадре можно искать определённые формы и объекты, которые могут содержаться только в порно. Приведу пример с женской грудью. В самом общем понимании её можно охарактеризовать как группу пикселов с "цветом кожи" овальной или круглой формы, внутри которой есть ещё одна группа пикселов более тёмного цвета. По идее, такой алгоритм сможет задетектить фронтальный план обнажённой груди без особых трудностей.
В кадре можно искать определённые формы и объекты, которые могут содержаться только в порно.
На самом деле этот подход едва ли не один из самых сложных в реализации. При обработке видео есть ряд нюансов, которых нет при обработке простых изображений: сложнее с определением цветов, низкое качество роликов (далеко не всё порно в HD, согласитесь), артефакты после сжатия различными кодеками, пикселизация и т.д. Да и определить форму объекта для программы порой весьма затруднительно. Смешно, но правда: детекторы формы часто путают то, что некоторые студенты кладут на учёбу, и большой палец.
Двигаемся дальше. И не просто двигаемся, а двигаемся ритмично.
Ритмичность движения на временном отрезке
Поиск ритмичного движения в кадре можно назвать основой основ при определении порноконтента. В теории всё выглядит довольно просто. Сущность классификации заключается в том, чтобы разделить некоторое множество объектов на два класса. Для этого:
- берётся тренировочное множество объектов, которые классифицируются вручную;
- создаётся процедура подбора параметров статистической модели;
- тренируем нашу модель на тренировочном множестве объектов;
- для оценки точности модели тестируем её на тестовом множестве.
Вот так всё просто. Но за этой мнимой простотой, как обычно, скрывается интересное техническое решение.
Еще раз про классификацию
Принцип работы большинства систем машинного обучения достаточно прост. Для классификации объектов на классы А и Б описывается совокупность их некоторых признаков (features), которые можно каким-либо образом измерить. Далее, статистически выводится формула или выражение, которая, если в нее подставить конкретные значения признаков для конкретного объекта, выдает значение >0 для объектов класса А, и значение <0 для объектов класса Б.
Например, мы хотим автоматически отличить, скажем, красную икру от черной. Признаки - цвет и размер икринки. Выберем несколько икринок черной и красной икры, измерим их и отразим ситуацию на графике.
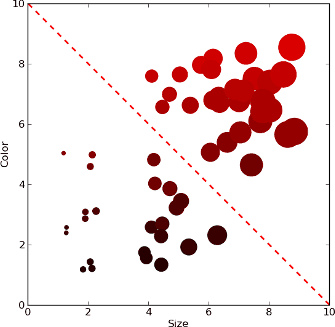
Пунктирная линия хорошо разделяет два имеющихся класса объектов. Видно, что красная икра крупнее и светлее черной. Построим формулу для этой линии, например:
z = размер * c1 - цвет * c2 + c0, где:
c1 и c2 - некоторые коэффициенты, статистически подобранные по результатам наблюдений;
c0 - константа.
В итоге, имея какую-то неизвестную икринку, мы подставим ее размер и цвет в нашу формулу, и при z>0 скажем, что икра красная, а при z<=0 - что она черная.
Это все, конечно, широко известно в узких кругах. Существует достаточно большое количество алгоритмов классификации. Например, при создании детекторов в рассматриваемом фильтре были использованы методы AdaBoost и Support Vector Machines.
Но вернёмся к теме - анализ ритмичности движения. Пожалуй, это один из самых важных признаков при классификации видеоконтента. Редко какой порноролик обходится без характерных ритмичных движений. Да, "татушки" знали, о чём пели. Что ж, приступим.
Анализ движений
Одним из известных и часто применяемых методов анализа движения является optical flow. Например, реализация optical flow присутствует в широко известной библиотеке OpenCV. Принцип работы напоминает поиск векторов движения при кодировании видео в формате mpeg - в одном кадре выбираются некоторые фрагменты изображения, которые ищутся в следующем кадре (например, методом SAD). Движение объектов соответствует смещению фрагментов изображения между кадрами.
Однако при реализации optical flow в детекторе порноконтента появляются нюансы:
- при наличии в изображении округлых, мягко освещенных форм (обнаженное тело) optical flow зачастую неправильно определяет направление движения;
- результаты работы - то есть, векторы движения - сложно классифицировать методами машинного обучения;
- даже при использовании собственной, оптимизированной реализации optical flow вместо OpenCV, затраты времени на вычисления получаются неприемлемо большими.
Как же быть?
Для определения направления движений используются пространственно-временные фильтры (spatiotemporal filters), основанные на применении операции свертки сигнала (convolution) и суммирования. Такой метод только начинает получать широкое распространение.
Давайте разберём применение свертки на простом, двухмерном примере. Допустим, вы применяете операцию "выделение края" (detect edges) к изображению в графическом редакторе.
Графический редактор создает маску размером 3x3, накладывает ее на изображение, начиная с каждого пиксела, перемножает соответствующие числа и суммирует результаты умножения. Результатом является одно число - можно сказать, что оно тем больше, чем сигнал под маской похож на саму маску.
Аналогичным образом, но в трехмерном пространстве (двумерные координаты пиксела в кадре + время или номер кадра в качестве третьего измерения), работают и использованные нами фильтры.
Как быть с видео?
- Кадры видеоролика собираются в "стопку";
- К получившейся структуре данных применяется операция трехмерной свертки. В этом случае можно создать маску, которая будет выдавать большие числа в случае наличия движения в каком-то заранее выбранном направлении с заранее выбранной скоростью;
- Применив несколько таких масок, можно оценить количество движения в каждом кадре, в каждом пикселе, в каждом из нескольких заранее выбранных направлений;
- Просуммировав значения результатов свертки сигнала во всех пикселах, можно качественно (по направлению) и количественно оценить движение в целом кадре в любой момент времени.

На рисунке ниже показан результат работы такого фильтра движения на небольшом отрывке порноролика.

Само видео можно увидеть на сайте авторов фильтра. Картинка в центре - текущий кадр из ролика. Картинки вокруг него - результат фильтрации последовательности кадров фильтрами. Каждый результат соответствует одному из двенадцати выбранных направлений движения. Зеленые кривые - это график количества движения в каждом направлении на протяжении нескольких десятков кадров.
Заметно, что характерные для порнографических роликов движения выражаются характерной, легко узнаваемой кривой. Также по этой кривой можно оценить количество персонажей в видеоролике и направления и скорость их движений.
В приведенном выше примере видео - два участника, двигающиеся в противоположных направлениях. Большие периодичные всплески на зеленой кривой соответствуют сильным движениям мужчины влево. Маленькие всплески соответствуют ответным движениям женщины и более слабым, возвратным движениям мужчины.
В случае присутствия лишь одного участника в видео (такое часто встречается в видеочатах), кривая не имеет вторых всплесков, чем-то напоминает синусоиду и легко поддается анализу. В случае трех или более участников ситуация значительно осложняется. Согласитесь, некоторые из редко встречающихся действий партнеров не могут быть смоделированы ни математически, ни даже описаны словесно.
Согласитесь, некоторые из редко встречающихся действий партнеров не могут быть смоделированы ни математически, ни даже описаны словесно.
Скорость движения также может быть использована для оценки времени акта. Если вы внимательно смотрели на данные ролика (а не на размытое изображение), то заметили, что, приближаясь к окончанию ролика, амплитуда движений увеличивается, а период - сокращается. К сожалению, данная оценка, скорее, представляет академический интерес, так как на практике является не слишком надёжным показателем.
Классификация движений
После того, как необходимые кривые были получены, осталось сделать последний шаг - научить компьютер отличать кривые, соответствующие порнографическим материалам, от других кривых. Тут тоже есть выбор методов, например:
- применение байесовских спам-фильтров,
- метод опорных векторов (SVM, support vector machines).
Для оценки кривых можно использовать существующие системы фильтрации словесного спама, основанные на методе Баейса. Каждая кривая может быть превращена в последовательность "слов" следующим образом:
- Выбирается некоторая длина слова. Каждое слово соответствует, скажем, 3 секундам из видео;
- Находится среднее значение амплитуды кривой на каждом отрезке времени;
- На каждом кадре, для каждой амплитуды кривой выше средней, добавляется к нашему "слову" "буква" 1, а для каждой амплитуды ниже средней - "буква" 0.
Таким образом, ролик превращается в набор "слов". Скажем, слова, похожие на 0110011, зачастую наблюдаются в порнороликах.
После превращения видеоролика в описание в виде набора таких "слов", тренировка обычного спам-фильтра для фильтрации порнографии - это уже просто дело техники.
Звук
Вот мы практически и добрались к финишной кривой. На мой взгляд, классификация звука по уровню сложности в реализации уступает детектору движений. Остановимся лишь на примерном описании подхода.
Вначале вручную отбирается тренировочное множество объектов, которое вырезается из порнороликов. Затем создаётся модель, обучается система, возвращается вероятность принадлежности ролика к порно.
Сам детектор звука основывается на двух основных параметрах:
- Наличие звука человеческого (преимущественно женского) голоса;
- Ритмичное повторение конкретных звуков. Для этого можно использовать вычисление mel-частотных кепстральных коэффициентов.
Таким образом, можно судить о наличии стонов (понятно, с некоторой вероятностью) в звуковом фрагменте. То есть, по этим двум параметрам детектор классифицирует фрагмент.
Заключение
В современном мире количество информации увеличивается даже не экспоненциально, и не в геометрической прогрессии. Всё происходит крайне быстро. Вместе с технологией изменяются и представления людей о хранении информации. Если ещё пару лет назад каждый считал своим долгом хранить любимую музыку на жёстком диске (а может на всякий случай ещё и на CD\DVD бэкап держать), то сейчас такие люди вызывают, скорее, удивление, чем понимание. Last.fm, prostopleer, googlemusic, appstore и прочие сервисы прочно укореняются на новых серверах, количество которых по последним данным выросло аж на 51%. Облачные технологии приходят на смену старым методам. Всё меняется и мы меняемся следом.
На разросшихся видеохостингах и файлообменных сервисах человек не в силах модерировать все входящие файлы. Только ведь статьи за "создание, хранение и распространение" не отменяли. В свете такой ситуации в процессе модерации человек отходит на "руководящую" должность, предоставляя делать "грязную" работу по отбору подозрительного контента машине.
Конечно, ни одна из систем не может дать 100% точности отбора. Представленные в статье подходы, к примеру, плохо сработают, если в порноролике будут участвовать темнокожие люди. Забавно, но факт: хуже всего всеми порнофильтрами ловятся BDSM-ролики. В них люди одеты, стонут не так, ритмичность отсутствует, а характерные формы в кадре зажаты в какие-нибудь тиски. Так что доверять весь процесс компьютеру ещё рано. Помните, только человек сможет сразу распознать, то ли это порно, то ли Фидель Кастро ест банан.
Конечно, ни одна из систем не может дать 100% точности отбора. Представленные в статье подходы, к примеру, плохо сработают, если в порноролике будут участвовать темнокожие люди.
Алексей ДРОЗД
При написании статьи использованы материалы:
- www.licenzero.ru/how
- www.antiporno.org/В-России-создана-технология-графической-фильтрации-порно-контента
- habrahabr.ru/blogs/data_mining/116173/
- www.securitylab.ru/news/405709.php
- habrahabr.ru/blogs/data_mining/117040/
- schoolseo.ru/2011/08/04/porno-kontentu-v-yandeks-kartinkax-netu-mesta/#more-2182
- it.siteua.org/ИТ-Новости/283316/Порнофильтр_для_поисковых_систем
- habrahabr.ru/blogs/data_mining/116625/
















Комментарии
Страницы
И что? Каждому админу по суперкомпу? Есть более действенные и более простые методы, хотя бы та же фильтрация url. Списки? Их есть в Инете. :)
Урлы и списки это да. Но подобные продукты нужны, к примеру, большим файлообменникам, видеохостингам. Их ведь по сути можно привлекать за хранение и распространение порнографии.
Дорогой автор, я бы постеснялся драть из хабра картинки. И вообще затея с порнофильтрами -- дорогой мыльный пузырь, так как доступны способы получать шифрованный порноконтент.
Вот поисковик по музыкальной фразе хорошо бы... Представляете -- напел в микрофон -- и получил ссылки. Такая вот идефикс.
Как программист и руководитель ИТ-проектов в прошлой жизни и отец в настоящей скажу, что тема актуальная. Алексей, предложенный Вами алгоритм простой по своему верхнему уровню (важно!) и, по-моему, полный. Если Вы будете реализовывать изложенное, по готовности конечного продукта познакомьте читателей, больно любопытно, получится ли и как получится. Удачи в реализации!
Приветствую беспрофильного пользователя, оперативно отреагировавшего. И что же вы пишете?
"Алексей, предложенный Вами алгоритм..."
Автор предлагал что-то СВОЁ?!
"...алгоритм простой по своему верхнему уровню"
Путаете способ и алгоритм. Простота кажущаяся. Способ очень ресурсопрожорлив и уж точно НЕ обеспечивает фильтрацию ВСЕХ видов извращений.
"Как ... отец в настоящей [жизни] скажу, что тема актуальная."
Согласен. Но для реализации ваших чаяний имеются вполне доступные и бесплатные порнофильтры, которые вы можете установить на домашний компьютер. Проверено: неплохо работает!
"Если Вы будете реализовывать изложенное, по готовности конечного продукта познакомьте читателей, больно любопытно, получится ли"
И мне "больно любопытно".
ИМХО так себе идея. У меня вот, например, нет музыкального слуха, поэтому страшно даже представить, что такой поисковик найдет, если я напою:)
Ну зачем же напевать. Вот, скажем, слушаете радио или смотрите ТВ. Тут -- бац! -- мелодия нравится, сразу жмак на компе кнопку записи фрагмента аудио. По нему и искать.
mike, в конце материала указаны ссылки на оригиналы статей, и на хабр в том числе. Не совсем понимаю ваши претензии.
Подобная идея давно реализована. Самым известным примером, пожалуй, уместно будет назвать Shazam. Официальной версии для PC у программы, кстати, нет.
Принцип работы схож с вашей "идефикс": включается запись фрагмента композиции на короткий промежуток времени (настраивается от 8 до 15 секунд), затем этот фрагмент "пробивается" по базам сервиса через интернет и выдаёт вам информацию по композиции. Название песни, исполнителя, альбом, год и пр.
Из фриварных ещё есть Tunatic. + ручные поделки.
По поводу "напел в микрофон" - идея гиблая. По крайней мере в том ключе, в котором вы предлагаете. Пока что единственный рабочий вариант "напел в микрофон - получил название песни" видится мне в комбинации распознавания речи (активно допиливается и совершенствуется на планшетах с андроидом) и гуглопоиска по lyrics.
Страницы