Сегодня на рынке RPA-платформ представлено множество решений, которые позволяют автоматизировать практически любой бизнес-процесс. Однако при работе с неструктурированными документами в формате PDF или JPG часто возникают проблемы с автоматизацией.
Для работы с ними обычного RPA-решения может оказаться недостаточно. Вместе со специалистами из ИТ-компании "Международный деловой альянс" разберемся, что такое умная автоматизация, какое место в ней занимает тегирование документов и какую пользу компаниям приносит этот метод.

Зачем нужна умная автоматизация в распознавании документов
Неструктурированные документы — это договоры с подрядчиками, счет-фактуры, обращения клиентов, письма. Из каждого такого документа программный робот должен извлечь определенные данные: дату заключения договора, сумму оплаты, имя и адрес отправителя, время отправки письма. Далее робот должен внести извлеченные данные в корпоративную систему документооборота, произвести вычисления или отправить уведомление отправителю. Это может оказаться сложной задачей.
Такие документы не имеют четкой структуры и универсальных форматов. Если разработчики RPA-решения хотят использовать строго описанные правила для обработки таких документов, это требует огромных затрат на разработку, поддержку и масштабирование решения.
Гораздо выгоднее и удобнее применять технологии машинного обучения, которые позволяют сделать автоматизацию "умной". Платформа, разработанная с применением таких технологий, называется Intelligent Automation Platform (IA Platform). Для обработки неструктурированных документов на ней необходимы три компонента. Далее рассмотрим, как они используются в работе платформы "Канцлер RPA".
Первый компонент работы с документами — распознавание
Для распознавания документов используются движки Optical Characters Recognition (OCR). Важными критериями при выборе являются качество распознавания отсканированных документов и возможность использования движка в коммерческих целях.
Разработчики платформы выбрали Tesseract OCR. Чтобы повысить качество распознавания, каждый документ проходит предобработку с помощью ImageMagick. Чаще всего достаточно базовой предобработки: изменения DPI изображения, обесцвечивания, выравнивания наклона, удаления прозрачности.
Эксперименты показывают, что оптимальное значение DPI можно рассчитать по высоте заглавных букв в тексте изображения. Минимальное количество ошибок Tesseract 4.0.0 допускает, когда заглавные буквы имеют размер 20-35 пикселей.
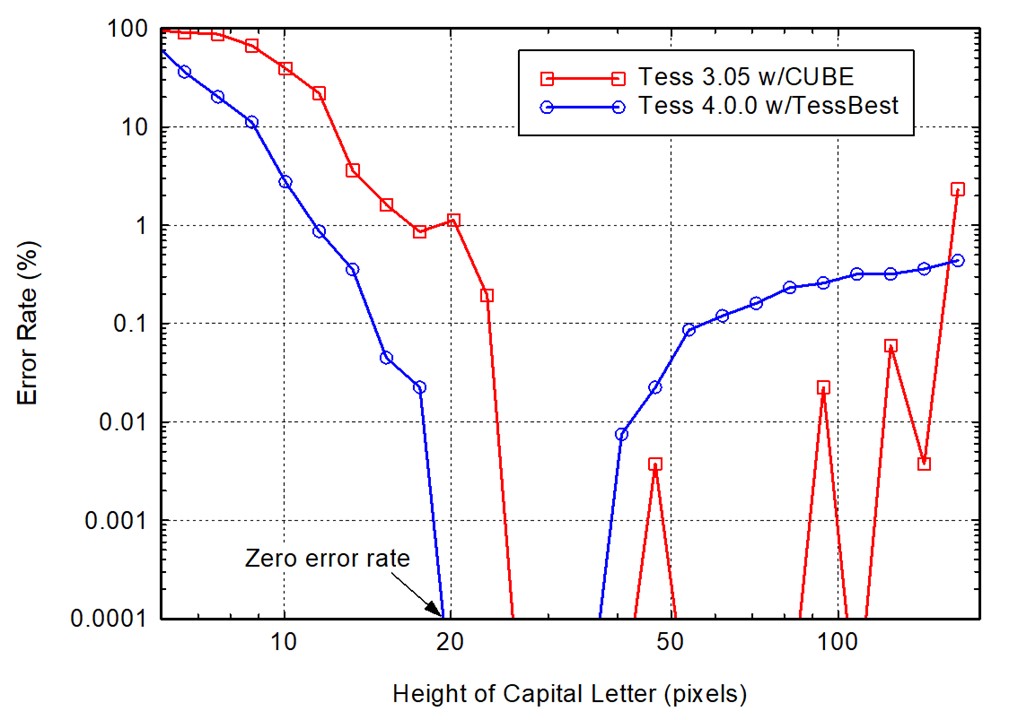
Точный размер зависит от используемого шрифта. Как правило, в большинстве официальных документов используются одни и те же шрифты. Поэтому разработчики определили, что при 350 DPI размер заглавных букв обычно и составляет 20-35 пикселей.
Вот пример документа, который прошел предобработку. В нем был исправлен наклон, увеличен контраст и использованы только черные и белые цвета:
Второй компонент работы с документами — тегирование
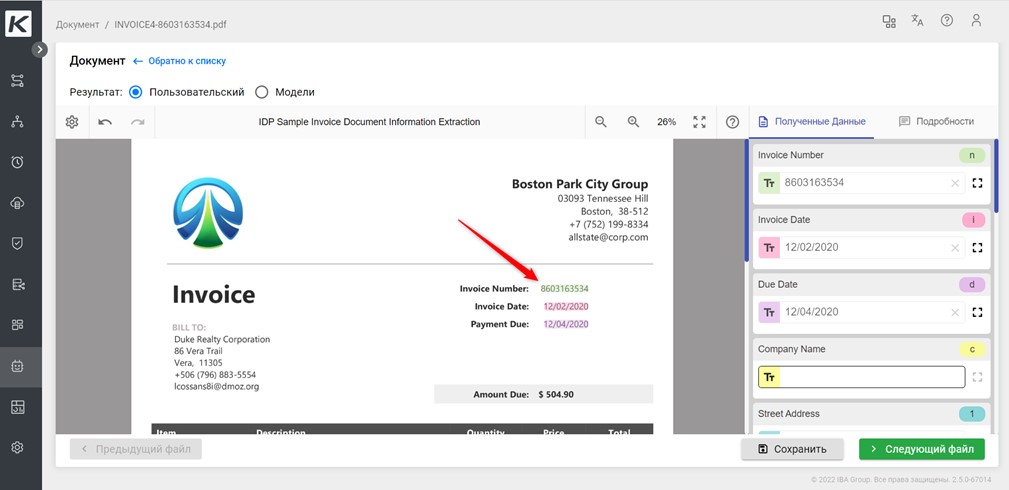
Чтобы робот смог правильно работать с документами, ему нужно сначала этому “научиться”. Для этого используется обучающий набор документов. Они похожи на те, которые будут использоваться в работе в дальнейшем, но не повторяют их на 100%. Чтобы подготовить такой обучающий набор, разработчики создали для платформы специальный вид ручной задачи: человек выделяет текст мышкой в документе, указывая системе расположение нужных данных. Для реализации этого компонента выбрали самую популярную библиотеку для создания пользовательских интерфейсов — ReactJS.
Обычно исходный документ имеет формат PDF. Он конвертируется в картинку с помощью ImageMagick и Ghost Script. Далее документ отправляется на OCR. После распознавания получается определенная HTML-структура: документ делится на страницы, страницы — на колонки, колонки — на параграфы и так далее. В атрибутах каждого блока есть информация о его расположении относительно оригинального документа. Таким образом, в итоге получается изображение оригинального документа и результат распознавания с координатами.
Далее система начинает отслеживать JS-события перемещения мыши по картинке и выделения. Когда человек выделяет область на картинке, в обработчике события отображаются координаты выделенной области. Далее можно легко определить, какие области из распознанного текста затрагивает выделенная область. Поскольку это нужно делать максимально быстро, для оптимизации процесса HTML конвертируется в JSON с сохранением структуры вложенности.
Если в выделенную человеком область попадает какое-то слово, создается элемент <div/> с полупрозрачным фоном с абсолютной позицией. Это имитирует выделение текста. Человеку кажется, что он выделил слово в самом документе, а на самом деле это просто картинка, на которой нет текстового слоя.
Данные, которые содержат в себе результат распознавания текста и координаты, в дальнейшем используются для обучения Machine Learning (ML) модели.
Третий компонент работы с документами — извлечение
Для автоматического извлечения текста применяется ML-библиотека SpaCy. Она использует нейронные сети и поддерживает 60+ языков. Под каждый вид документов нужно обучить отдельную модель. Благодаря компоненту тегирования, который мы рассмотрели выше, это могут делать сотрудники, которые до автоматизации занимались той же работой вручную. Знания в RPA или ML им для этого не нужны.
Для обучающего набора достаточно от 50 до 100 документов. После того, как модель “научится” с ними работать, она уже сможет приносить пользу заказчику. Однако эксперименты показали, что оптимальное количество документов — 500.
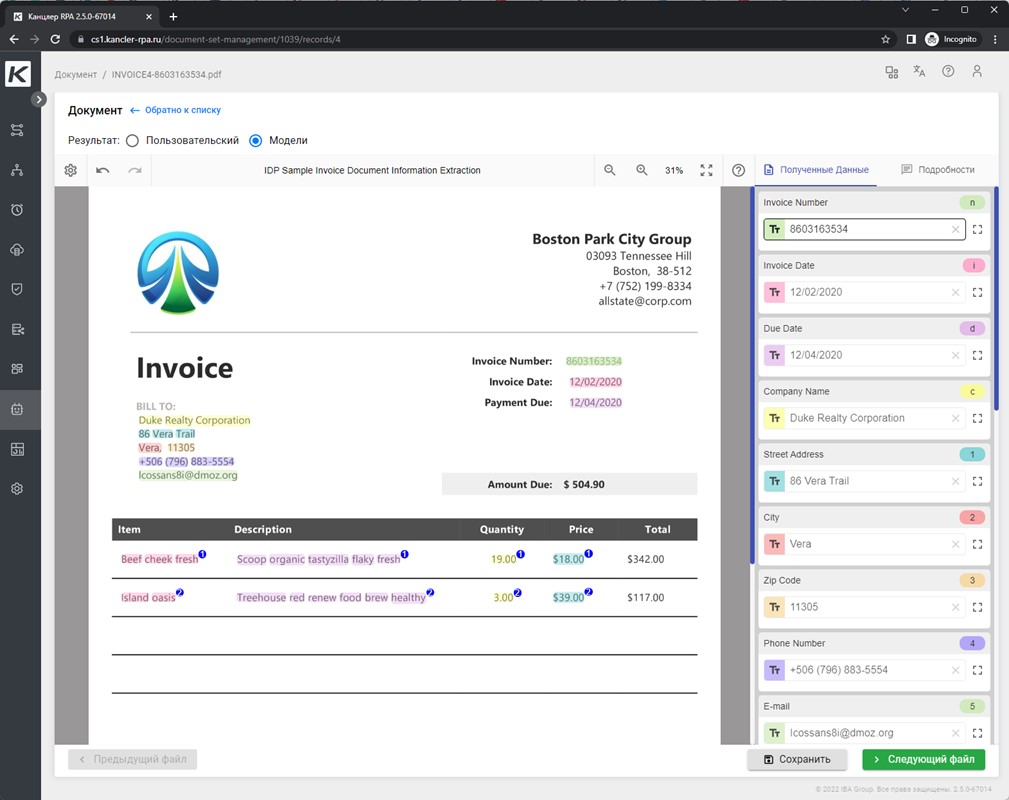
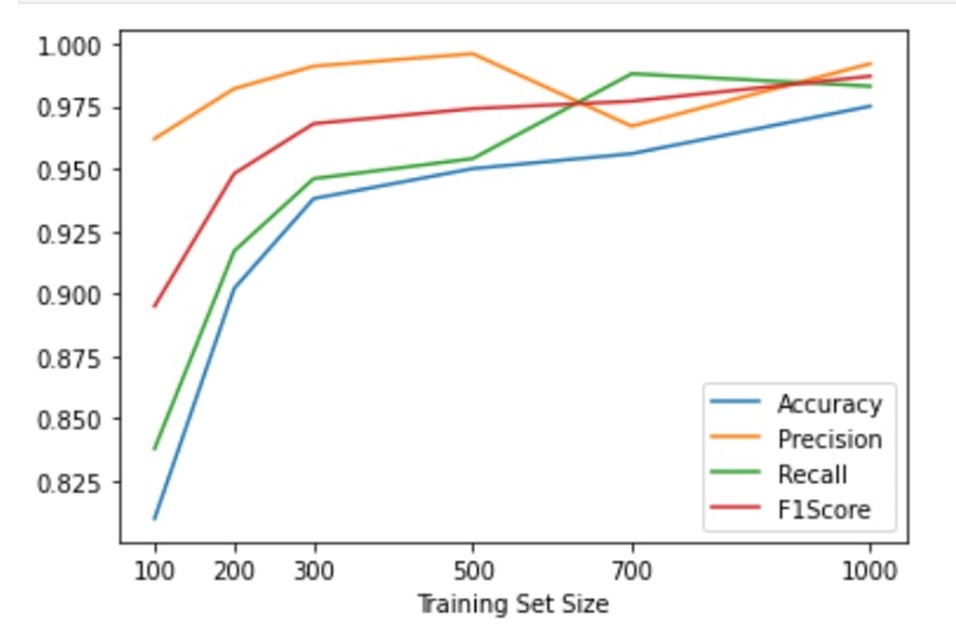 Когда модель прошла обучение, ее можно внедрять в бизнес-процесс. Она будет тегировать документ автоматически, без участия человека. Однако, при необходимости человек может вмешаться в процесс и посмотреть, как и откуда были извлечены данные.
Когда модель прошла обучение, ее можно внедрять в бизнес-процесс. Она будет тегировать документ автоматически, без участия человека. Однако, при необходимости человек может вмешаться в процесс и посмотреть, как и откуда были извлечены данные.
Где сегодня применяются роботы при работе с документами
Робот умеет выполнять все те же действия, которые выполняет в офисе обычный сотрудник:
- искать, копировать и вставлять данные;
- переходить по ссылкам;
- производить математические вычисления;
- распознавать текст;
- создавать таблицы;
- заполнять формы;
- сравнивать информацию в разных корпоративных системах.
Большое преимущество робота в том, что он отлично справляется с задачами, которые необходимо выполнять строго по расписанию. Программа запускается точно в срок, работает с данными, формирует отчеты, отправляет письма и уведомления. Она все успеет и ничего не забудет.

Вывод: почему умная автоматизация в тренде
Роботы — это новые сотрудники компании, которые готовы работать 24/7 без перерывов на обед. Они помогают повысить эффективность работы, освобождая сотрудников для более сложных и важных задач. А самое главное — внедрение роботов не требует изменения ИТ-инфраструктуры компании.
Компании, которые не хотят автоматизировать всю работу с документами, могут выбрать платформу, в которой есть демо-версия или возможность пробного использования без платы за лицензию. Умные RPA-платформы отлично справляются с обработкой неструктурированных документов. А как мы увидели, большинство документов, с которыми приходится иметь дело офисным работникам, являются неструктурированными.

















Горячие темы